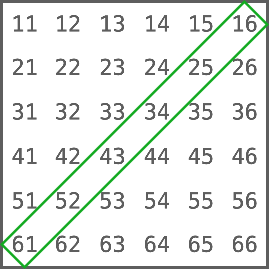
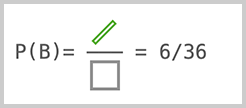
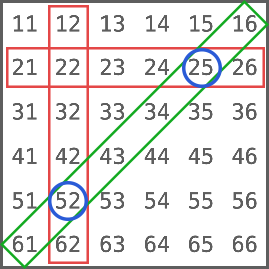
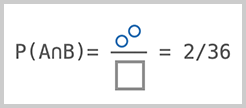https://liaoxuefeng.com/books/javascript/introduction/index.html摘自
下面的一行代码包含两个语句,每个语句用;表示语句结束
var x = 1; var y = 2; // 定义了两个变量,不建议一行写多个语句!
用等号=对变量进行赋值。可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量,但是要注意只能用var申明一次,例如:
var a = 123; // a的值是整数123
a = 'ABC'; // a变为字符串
这种变量本身类型不固定的语言称之为动态语言
如果一个变量没有通过var申明就被使用,那么该变量就自动被申明为全局变量:
i = 10; // i现在是全局变量
在同一个页面的不同的JavaScript文件中,如果都不用var申明,恰好都使用了变量i,将造成变量i互相影响,产生难以调试的错误结果。这是要避免的,可以在JavaScript代码的第一行写上:’use strict’;强制要求通过var申明变量
const来定义常量,比如const PI = 3.1415926要求数值一定后面不能改,可以用这个定义
语句块是一组语句的集合,例如,下面的代码先做了一个判断,如果判断成立,将执行{...}中的所有语句:
if (2 > 1) {
x = 1;
y = 2;
z = 3;
}
注意花括号{...}内的语句具有缩进,通常是4个空格。缩进不是JavaScript语法要求必须的
以//开头直到行末的字符被视为行注释, /*...*/把多行字符包裹起来
JavaScript不区分整数和浮点数,统一用Number表示,以下都是合法的Number类型:
123; // 整数123
0.456; // 浮点数0.456
1.2345e3; // 科学计数法表示1.2345x1000,等同于1234.5
-99; // 负数
NaN; // NaN表示Not a Number,当无法计算结果时用NaN表示
Infinity; // Infinity表示无限大,当数值超过了JavaScript的Number所能表示的最大值时,就表示为Infinity
计算机由于使用二进制,所以,有时候用十六进制表示整数比较方便,十六进制用0x前缀和0-9,a-f表示,例如:0xff00,0xa5b4c3d2,等等,它们和十进制表示的数值完全一样。
Number可以直接做四则运算,规则和数学一致:
1 + 2; // 3
(1 + 2) * 5 / 2; // 7.5
2 / 0; // Infinity
0 / 0; // NaN
10 % 3; // 1
10.5 % 3; // 1.5
注意%是求余运算。
要注意,JavaScript的Number不区分整数和浮点数,也就是说,12.00 === 12。(在大多数其他语言中,整数和浮点数不能直接比较)并且,JavaScript的整数最大范围不是±263,而是±253,因此,超过253的整数就可能无法精确表示:,如果一串字符很长且不是计算则尽量要把他变成字符串,否则会把后面截去影响结果
// 计算圆面积:
var r = 123.456;
var s = 3.14 * r * r;
console.log(s); // 47857.94555904001
字符串是以单引号’或双引号”括起来的任意文本,比如'abc',"xyz"等等。请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这3个字符
&&运算是与运算,只有所有都为true,&&运算结果才是true:
true && true; // 这个&&语句计算结果为true
true && false; // 这个&&语句计算结果为false
false && true && false; // 这个&&语句计算结果为false
||运算是或运算,只要其中有一个为true,||运算结果就是true:
false || false; // 这个||语句计算结果为false
true || false; // 这个||语句计算结果为true
false || true || false; // 这个||语句计算结果为true
!运算是非运算,它是一个单目运算符,把true变成false,false变成true:
! true; // 结果为false
实际上,JavaScript允许对任意数据类型做比较:
false == 0; // true
false === 0; // false
要特别注意相等运算符==。JavaScript在设计时,有两种比较运算符:
第一种是==比较,它会自动转换数据类型再比较,很多时候,会得到非常诡异的结果;
第二种是===比较,它不会自动转换数据类型,如果数据类型不一致,返回false,如果一致,再比较。
由于JavaScript这个设计缺陷,不要使用==比较,始终坚持使用===比较。
另一个例外是NaN这个特殊的Number与所有其他值都不相等,包括它自己:
NaN === NaN; // false
唯一能判断NaN的方法是通过isNaN()函数:
isNaN(NaN); // true
最后要注意浮点数的相等比较:
1 / 3 === (1 - 2 / 3); // false
这不是JavaScript的设计缺陷。浮点数在运算过程中会产生误差,因为计算机无法精确表示无限循环小数。要比较两个浮点数是否相等,只能计算它们之差的绝对值,看是否小于某个阈值:
Math.abs(1 / 3 - (1 - 2 / 3)) < 0.0000001; // true
null和undefined
null表示一个“空”的值,它和0以及空字符串''不同,0是一个数值,''表示长度为0的字符串,而null表示“空”。
在其他语言中,也有类似JavaScript的null的表示,例如Java也用null,Swift用nil,Python用None表示。但是,在JavaScript中,还有一个和null类似的undefined,它表示“未定义”。
JavaScript的设计者希望用null表示一个空的值,而undefined表示值未定义。事实证明,这并没有什么卵用,区分两者的意义不大。大多数情况下,我们都应该用null。undefined仅仅在判断函数参数是否传递的情况下有用
数组是一组按顺序排列的集合,集合的每个值称为元素。JavaScript的数组可以包括任意数据类型。例如:
[1, 2, 3.14, 'Hello', null, true];
上述数组包含6个元素。数组用[]表示,元素之间用,分隔。
另一种创建数组的方法是通过Array()函数实现:
new Array(1, 2, 3); // 创建了数组[1, 2, 3]
JavaScript的对象是一组由键-值组成的无序集合,例如:
var person = {
name: 'Bob',
age: 20,
tags: ['js', 'web', 'mobile'],
city: 'Beijing',
hasCar: true,
zipcode: null
};
JavaScript对象的键都是字符串类型,值可以是任意数据类型。
要获取一个对象的属性,我们用对象变量.属性名的方式:
person.name; // 'Bob'
person.zipcode; // null
JavaScript的字符串就是用''或""括起来的字符表示。
如果'本身也是一个字符,那就可以用""括起来,比如"I'm OK"
如果字符串内部既包含'又包含"怎么办?可以用转义字符\来标识,比如:
'I\'m \"OK\"!'; // I'm "OK"!
表示的字符串内容是:I'm "OK"!
转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\。
ASCII字符可以以\x##形式的十六进制表示,例如:
'\x41'; // 完全等同于 'A'
还可以用\u####表示一个Unicode字符:
'\u4e2d\u6587'; // 完全等同于 '中文'
多行字符串用\n写起来比较费事,用反引号`...`表示
多个字符串连接起来,可以用+号连接
如果有很多变量需要连接,用+号就比较麻烦。ES6新增了一种模板字符串,它会自动替换字符串中的变量:
let name = '小明';
let age = 20;
let message = `你好, ${name}, 你今年${age}岁了!`;
alert(message);
获取字符串长度:
let s = 'Hello, world!';
s.length; // 13
要获取字符串某个指定位置的字符,使用类似Array的下标操作,索引号从0开始:
let s = 'Hello, world!';
s[0]; // 'H'
s[6]; // ' '
s[7]; // 'w'
s[12]; // '!'
s[13]; // undefined 超出范围的索引不会报错,但一律返回undefined
需要特别注意的是,字符串是不可变的,如果对字符串的某个索引赋值,不会有任何错误,但是,也没有任何效果:
let s = 'Test';
s[0] = 'X';
console.log(s); // s仍然为'Test'
JavaScript为字符串提供了一些常用方法,注意,调用这些方法本身不会改变原有字符串的内容,而是返回一个新字符串:
toUpperCase
toUpperCase()把一个字符串全部变为大写:
let s = 'Hello';
s.toUpperCase(); // 返回'HELLO'
toLowerCase
toLowerCase()把一个字符串全部变为小写:
let s = 'Hello';
let lower = s.toLowerCase(); // 返回'hello'并赋值给变量lower
lower; // 'hello'
indexOf
indexOf()会搜索指定字符串出现的位置:
let s = 'hello, world';
s.indexOf('world'); // 返回7
s.indexOf('World'); // 没有找到指定的子串,返回-1
substring
substring()返回指定索引区间的子串:
let s = 'hello, world'
s.substring(0, 5); // 从索引0开始到5(不包括5),返回'hello'
s.substring(7); // 从索引7开始到结束,返回'world'
Array可以包含任意数据类型,并通过索引来访问每个元素
indexOf
与String类似,Array也可以通过indexOf()来搜索一个指定的元素的位置:
let arr = [10, 20, '30', 'xyz'];
arr.indexOf(10); // 元素10的索引为0
arr.indexOf(20); // 元素20的索引为1
arr.indexOf(30); // 元素30没有找到,返回-1
arr.indexOf('30'); // 元素'30'的索引为2
注意了,数字30和字符串'30'是不同的元素。
slice
slice()就是对应String的substring()版本,它截取Array的部分元素,然后返回一个新的Array:
let arr = ['A', 'B', 'C', 'D', 'E', 'F', 'G'];
arr.slice(0, 3); // 从索引0开始,到索引3结束,但不包括索引3: ['A', 'B', 'C']
arr.slice(3); // 从索引3开始到结束: ['D', 'E', 'F', 'G']
注意到slice()的起止参数包括开始索引,不包括结束索引。
如果不给slice()传递任何参数,它就会从头到尾截取所有元素。利用这一点,我们可以很容易地复制一个Array:
let arr = ['A', 'B', 'C', 'D', 'E', 'F', 'G'];
let aCopy = arr.slice();
aCopy; // ['A', 'B', 'C', 'D', 'E', 'F', 'G']
aCopy === arr; // false
push和pop
push()向Array的末尾添加若干元素,pop()则把Array的最后一个元素删除掉:
let arr = [1, 2];
arr.push('A', 'B'); // 返回Array新的长度: 4
arr; // [1, 2, 'A', 'B']
arr.pop(); // pop()返回'B'
arr; // [1, 2, 'A']
arr.pop(); arr.pop(); arr.pop(); // 连续pop 3次
arr; // []
arr.pop(); // 空数组继续pop不会报错,而是返回undefined
arr; // []
unshift和shift
如果要往Array的头部添加若干元素,使用unshift()方法,shift()方法则把Array的第一个元素删掉:
let arr = [1, 2];
arr.unshift('A', 'B'); // 返回Array新的长度: 4
arr; // ['A', 'B', 1, 2]
arr.shift(); // 'A'
arr; // ['B', 1, 2]
arr.shift(); arr.shift(); arr.shift(); // 连续shift 3次
arr; // []
arr.shift(); // 空数组继续shift不会报错,而是返回undefined
arr; // []
sort
sort()可以对当前Array进行排序,它会直接修改当前Array的元素位置,直接调用时,按照默认顺序排序:
let arr = ['B', 'C', 'A'];
arr.sort();
arr; // ['A', 'B', 'C']
能否按照我们自己指定的顺序排序呢?完全可以,我们将在后面的函数中讲到。
reverse
reverse()把整个Array的元素给调个个,也就是反转:
let arr = ['one', 'two', 'three'];
arr.reverse();
arr; // ['three', 'two', 'one']
splice
splice()方法是修改Array的“万能方法”,它可以从指定的索引开始删除若干元素,然后再从该位置添加若干元素:
let arr = ['Microsoft', 'Apple', 'Yahoo', 'AOL', 'Excite', 'Oracle'];
// 从索引2开始删除3个元素,然后再添加两个元素:
arr.splice(2, 3, 'Google', 'Facebook'); // 返回删除的元素 ['Yahoo', 'AOL', 'Excite']
arr; // ['Microsoft', 'Apple', 'Google', 'Facebook', 'Oracle']
// 只删除,不添加:
arr.splice(2, 2); // ['Google', 'Facebook']
arr; // ['Microsoft', 'Apple', 'Oracle']
// 只添加,不删除:
arr.splice(2, 0, 'Google', 'Facebook'); // 返回[],因为没有删除任何元素
arr; // ['Microsoft', 'Apple', 'Google', 'Facebook', 'Oracle']
concat
concat()方法把当前的Array和另一个Array连接起来,并返回一个新的Array:
let arr = ['A', 'B', 'C'];
let added = arr.concat([1, 2, 3]);
added; // ['A', 'B', 'C', 1, 2, 3]
arr; // ['A', 'B', 'C']
请注意,concat()方法并没有修改当前Array,而是返回了一个新的Array。
实际上,concat()方法可以接收任意个元素和Array,并且自动把Array拆开,然后全部添加到新的Array里:
let arr = ['A', 'B', 'C'];
arr.concat(1, 2, [3, 4]); // ['A', 'B', 'C', 1, 2, 3, 4]
join
join()方法是一个非常实用的方法,它把当前Array的每个元素都用指定的字符串连接起来,然后返回连接后的字符串:
let arr = ['A', 'B', 'C', 1, 2, 3];
arr.join('-'); // 'A-B-C-1-2-3'
JavaScript的对象有个小问题,就是键必须是字符串。但实际上Number或者其他数据类型作为键也是非常合理的。
为了解决这个问题,最新的ES6规范引入了新的数据类型Map
Map是一组键值对的结构,具有极快的查找速度。
举个例子,假设要根据同学的名字查找对应的成绩,如果用Array实现,需要两个Array:
let names = ['Michael', 'Bob', 'Tracy'];
let scores = [95, 75, 85];
给定一个名字,要查找对应的成绩,就先要在names中找到对应的位置,再从scores取出对应的成绩,Array越长,耗时越长。
如果用Map实现,只需要一个“名字”-“成绩”的对照表,直接根据名字查找成绩,无论这个表有多大,查找速度都不会变慢。用JavaScript写一个Map如下:
let m = new Map([['Michael', 95], ['Bob', 75], ['Tracy', 85]]);
m.get('Michael'); // 95
初始化Map需要一个二维数组,或者直接初始化一个空Map。Map具有以下方法:
let m = new Map(); // 空Map
m.set('Adam', 67); // 添加新的key-value
m.set('Bob', 59);
m.has('Adam'); // 是否存在key 'Adam': true
m.get('Adam'); // 67
m.delete('Adam'); // 删除key 'Adam'
m.get('Adam'); // undefined
Set和Map类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在Set中,没有重复的key。
要创建一个Set,需要提供一个Array作为输入,或者直接创建一个空Set:
let s1 = new Set(); // 空Set
let s2 = new Set([1, 2, 3]); // 含1, 2, 3
重复元素在Set中自动被过滤:
let s = new Set([1, 2, 3, 3, '3']);
s; // Set {1, 2, 3, "3"}
注意数字3和字符串'3'是不同的元素。
通过add(key)方法可以添加元素到Set中,可以重复添加,但不会有效果:
s.add(4);
s; // Set {1, 2, 3, 4}
s.add(4);
s; // 仍然是 Set {1, 2, 3, 4}
通过delete(key)方法可以删除元素
遍历Array可以采用下标循环,遍历Map和Set就无法使用下标。为了统一集合类型,ES6标准引入了新的iterable类型,Array、Map和Set都属于iterable类型。
具有iterable类型的集合可以通过新的for ... of循环来遍历
let a = ['A', 'B', 'C'];
let s = new Set(['A', 'B', 'C']);
let m = new Map([[1, 'x'], [2, 'y'], [3, 'z']]);
for (let x of a) { // 遍历Array
console.log(x);
}
for (let x of s) { // 遍历Set
console.log(x);
}
for (let x of m) { // 遍历Map
console.log(x[0] + '=' + x[1]);
}
我们建议用for … of,而不是for … in 更好的方式是直接使用iterable内置的forEach方法,它接收一个函数,每次迭代就自动回调该函数。以Array为例:
let a = [‘A’, ‘B’, ‘C’];
a.forEach(function (element, index, array) {
// element: 指向当前元素的值
// index: 指向当前索引
// array: 指向Array对象本身
console.log(${element}, index = ${index});
});
关键字arguments,它只在函数内部起作用,并且永远指向当前函数的调用者传入的所有参数
实际上arguments最常用于判断传入参数的个数。你可能会看到这样的写法:
// foo(a[, b], c)
// 接收2~3个参数,b是可选参数,如果只传2个参数,b默认为null:
function foo(a, b, c) {
if (arguments.length === 2) {
// 实际拿到的参数是a和b,c为undefined
c = b; // 把b赋给c
b = null; // b变为默认值
}
// ...
}
由于JavaScript函数允许接收任意个参数,于是我们就不得不用arguments来获取所有参数:
function foo(a, b) {
let i, rest = [];
if (arguments.length > 2) {
for (i = 2; i<arguments.length; i++) {
rest.push(arguments[i]);
}
}
console.log('a = ' + a);
console.log('b = ' + b);
console.log(rest);
}
为了获取除了已定义参数a、b之外的参数,我们不得不用arguments,并且循环要从索引2开始以便排除前两个参数,这种写法很别扭,只是为了获得额外的rest参数,有没有更好的方法?
ES6标准引入了rest参数,上面的函数可以改写为:
function foo(a, b, ...rest) {
console.log('a = ' + a);
console.log('b = ' + b);
console.log(rest);
}
foo(1, 2, 3, 4, 5);
// 结果:
// a = 1
// b = 2
// Array [ 3, 4, 5 ]
foo(1);
// 结果:
// a = 1
// b = undefined
// Array []
rest参数只能写在最后,前面用...标识,从运行结果可知,传入的参数先绑定a、b,多余的参数以数组形式交给变量rest,所以,不再需要arguments我们就获取了全部参数。
如果传入的参数连正常定义的参数都没填满,也不要紧,rest参数会接收一个空数组(注意不是undefined)
JavaScript默认有一个全局对象window,全局作用域的变量实际上被绑定到window的一个属性,以变量方式var foo = function () {}定义的函数实际上也是一个全局变量,因此,顶层函数的定义也被视为一个全局变量,并绑定到window对象:
function foo() {
alert('foo');
}
foo(); // 直接调用foo()
window.foo(); // 通过window.foo()调用
进一步大胆地猜测,我们每次直接调用的alert()函数其实也是window的一个变量
高阶函数
map
举例说明,比如我们有一个函数f(x)=x2,要把这个函数作用在一个数组[1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map实现如下:
f(x) = x * x
│
│
┌───┬───┬───┬───┼───┬───┬───┬───┐
│ │ │ │ │ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼
[ 1 2 3 4 5 6 7 8 9 ]
│ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼
[ 1 4 9 16 25 36 49 64 81 ]
由于map()方法定义在JavaScript的Array中,我们调用Array的map()方法,传入我们自己的函数,就得到了一个新的Array作为结果:
function pow(x) {
return x * x;
}
let arr = [1, 2, 3, 4, 5, 6, 7, 8, 9];
let results = arr.map(pow); //结果 [1, 4, 9, 16, 25, 36, 49, 64, 81]
要区别于上页的Map,上面的Map是一个数据结构,一些键值对,这里是一个高阶函数
reduce
再看reduce的用法。Array的reduce()把一个函数作用在这个Array的[x1, x2, x3...]上,这个函数必须接收两个参数,reduce()把结果继续和序列的下一个元素做累积计算,其效果就是:
[x1, x2, x3, x4].reduce(f) = f(f(f(x1, x2), x3), x4)
比方说对一个Array求和,就可以用reduce实现:
let arr = [1, 3, 5, 7, 9];
arr.reduce(function (x, y) {
return x + y;
}); // 25
filter也是一个常用的操作,它用于把Array的某些元素过滤掉,然后返回剩下的元素。
filter()把传入的函数依次作用于每个元素,然后根据返回值是true还是false决定保留还是丢弃该元素。
例如,在一个Array中,删掉偶数,只保留奇数,可以这么写:
let arr = [1, 2, 4, 5, 6, 9, 10, 15];
let r = arr.filter(function (x) {
return x % 2 !== 0;
});
r; // [1, 5, 9, 15]
sort()方法是用于排序的, 要注意的是默认把所有元素先转换为String再排序,所以'10'排在了'2'的前面,因为字符'1'比字符'2'的ASCII码小,幸运的是,sort()方法也是一个高阶函数,它还可以接收一个比较函数来实现自定义的排序。
要按数字大小排序,我们可以这么写:
let arr = [10, 20, 1, 2];
arr.sort(function (x, y) {
if (x < y) { return -1; } if (x > y) {
return 1;
}
return 0;
});
console.log(arr); // [1, 2, 10, 20]
every()方法可以判断数组的所有元素是否满足测试条件
find()方法用于查找符合条件的第一个元素,如果找到了,返回这个元素,否则,返回undefined
findIndex()和find()类似,也是查找符合条件的第一个元素,不同之处在于findIndex()会返回这个元素的索引,如果没有找到,返回-1
forEach()和map()类似,它也把每个元素依次作用于传入的函数,但不会返回新的数组。forEach()常用于遍历数组,因此,传入的函数不需要返回值:
let arr = [‘Apple’, ‘pear’, ‘orange’];
arr.forEach(x=>console.log(x)); // 依次打印每个元素
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回
箭头函数
x => x * x
上面的箭头函数相当于:
function (x) {
return x * x;
}
还有一种可以包含多条语句,这时候就不能省略{ ... }和return:
x => {
if (x > 0) {
return x * x;
}
else {
return - x * x;
}
}
如果参数不是一个,就需要用括号()括起来
标签函数
const email = “test@example.com”;
const password = ‘hello123’;
function sql(strings, …exps) {
console.log(SQL: ${strings.join('?')});
console.log(SQL parameters: ${JSON.stringify(exps)});
return {
name: ‘小明’,
age: 20
};
}
const result = sqlSELECT * FROM users WHERE email=${email} AND password=${password};
console.log(JSON.stringify(result));
这里出现了一个奇怪的语法:
sql`SELECT * FROM users WHERE email=${email} AND password=${password}`
模板字符串前面以sql开头,实际上这是一个标签函数,上述语法会自动转换为对sql()函数的调用。我们关注的是,传入sql()函数的参数是什么。
sql()函数实际上接收两个参数:
第一个参数strings是一个字符串数组,它是["SELECT * FROM users WHERE email=", " AND password=", ""],即除去${xxx}剩下的字符组成的数组;
第二个参数...exps是一个可变参数,它接收的也是一个数组,但数组的内容是由模板字符串里所有的${xxx}的实际值组成,即["test@example.com", "hello123"],因为解析${email}得到"test@example.com",解析${password}得到"hello123"。
生成器 generator由function*定义(注意多出的*号)
调用generator对象有两个方法,一是不断地调用generator对象的next()方法
第二个方法是直接用for ... of循环迭代generator对象
function* fib(max) {
let
a = 0,
b = 1,
n = 0;
while (n < max) {
yield a;
[a, b] = [b, a + b];
n ++;
}
return;
}
for (let x of fib(10)) {
console.log(x); // 依次输出0, 1, 1, 2, 3, ...
}
在JavaScript中,Date对象用来表示日期和时间。
要获取系统当前时间,用:
let now = new Date();
now; // Wed Jun 24 2015 19:49:22 GMT+0800 (CST)
now.getFullYear(); // 2015, 年份
now.getMonth(); // 5, 月份,注意月份范围是0~11,5表示六月
now.getDate(); // 24, 表示24号
now.getDay(); // 3, 表示星期三
now.getHours()
JavaScript有两种方式创建一个正则表达式:
第一种方式是直接通过/正则表达式/写出来,第二种方式是通过new RegExp('正则表达式')创建一个RegExp对象。
两种写法是一样的:
let re1 = /ABC\-001/;
let re2 = new RegExp('ABC\\-001');
re1; // /ABC\-001/
re2; // /ABC\-001/
注意,如果使用第二种写法,因为字符串的转义问题,字符串的两个\\实际上是一个\。
先看看如何判断正则表达式是否匹配:
let re = /^\d{3}\-\d{3,8}$/;
re.test('010-12345'); // true
re.test('010-1234x'); // false
re.test('010 12345'); // false
RegExp对象的test()方法用于测试给定的字符串是否符合条件
JSON是JavaScript Object Notation的缩写,它是一种数据交换格式,JSON实际上是JavaScript的一个子集。在JSON中,一共就这么几种数据类型:
- number:和JavaScript的
number完全一致;
- boolean:就是JavaScript的
true或false;
- string:就是JavaScript的
string;
- null:就是JavaScript的
null;
- array:就是JavaScript的
Array表示方式——[];
- object:就是JavaScript的
{ ... }表示方式。
以及上面的任意组合。
并且,JSON还定死了字符集必须是UTF-8,表示多语言就没有问题了。为了统一解析,JSON的字符串规定必须用双引号"",Object的键也必须用双引号""。
拿到一个JSON格式的字符串,我们直接用JSON.parse()把它反序列化变成一个JavaScript对象
JSON.stringify()把一个JavaScript对象序列化为JSON
对象编程
创建一个Array对象:
let arr = [1, 2, 3];
当我们创建一个函数时:
function foo() {
return 0;
}
函数也是一个对象,
构造函数
除了直接用{ ... }创建一个对象外,JavaScript还可以用一种构造函数的方法来创建对象。它的用法是,先定义一个构造函数:
function Student(name) {
this.name = name;
this.hello = function () {
alert('Hello, ' + this.name + '!');
}
}
你会问,咦,这不是一个普通函数吗?
这确实是一个普通函数,但是在JavaScript中,可以用关键字new来调用这个函数,并返回一个对象:
let xiaoming = new Student('小明');
xiaoming.name; // '小明'
xiaoming.hello(); // Hello, 小明!
注意,如果不写new,这就是一个普通函数,它返回undefined。但是,如果写了new,它就变成了一个构造函数,它绑定的this指向新创建的对象,并默认返回this,也就是说,不需要在最后写return this;。
JavaScript可以获取浏览器提供的很多对象,并进行操作。
window
window对象不但充当全局作用域,而且表示浏览器窗口。
window对象有innerWidth和innerHeight属性,可以获取浏览器窗口的内部宽度和高度的内部宽度和高度
navigator
navigator对象表示浏览器的信息,最常用的属性包括:
- navigator.appName:浏览器名称;
- navigator.appVersion:浏览器版本;
- navigator.language:浏览器设置的语言;
- navigator.platform:操作系统类型;
- navigator.userAgent:浏览器设定的
User-Agent字符串
screen对象表示屏幕的信息
location对象表示当前页面的URL信息。例如,一个完整的URL,可以用location.href获取
document对象表示当前页面。由于HTML在浏览器中以DOM形式表示为树形结构,document对象就是整个DOM树的根节点。
document的title属性是从HTML文档中的<title>xxx</title>读取的
要查找DOM树的某个节点,需要从document对象开始查找。最常用的查找是根据ID和Tag Name。
JavaScript可以通过document.cookie读取到当前页面的Cookie
由于HTML文档被浏览器解析后就是一棵DOM树,要改变HTML的结构,就需要通过JavaScript来操作DOM。
始终记住DOM是一个树形结构。操作一个DOM节点实际上就是这么几个操作:
- 更新:更新该DOM节点的内容,相当于更新了该DOM节点表示的HTML的内容;
- 遍历:遍历该DOM节点下的子节点,以便进行进一步操作;
- 添加:在该DOM节点下新增一个子节点,相当于动态增加了一个HTML节点;
- 删除:将该节点从HTML中删除,相当于删掉了该DOM节点的内容以及它包含的所有子节点。
在操作一个DOM节点前,我们需要通过各种方式先拿到这个DOM节点。最常用的方法是document.getElementById()和document.getElementsByTagName(),以及CSS选择器document.getElementsByClassName()。
由于ID在HTML文档中是唯一的,所以document.getElementById()可以直接定位唯一的一个DOM节点。document.getElementsByTagName()和document.getElementsByClassName()总是返回一组DOM节点。要精确地选择DOM,可以先定位父节点,再从父节点开始选择,以缩小范围。
第二种方法是使用querySelector()和querySelectorAll(),需要了解selector语法,然后使用条件来获取节点,更加方便:
// 通过querySelector获取ID为q1的节点:
let q1 = document.querySelector('#q1');
// 通过querySelectorAll获取q1节点内的符合条件的所有节点:
let ps = q1.querySelectorAll('div.highlighted > p');
拿到一个DOM节点后,我们可以对它进行更新。
可以直接修改节点的文本,方法有两种:
一种是修改innerHTML属性,这个方式非常强大,不但可以修改一个DOM节点的文本内容,还可以直接通过HTML片段修改DOM节点内部的子树:
// 获取<p id="p-id">...</p>
let p = document.getElementById('p-id');
// 设置文本为abc:
p.innerHTML = 'ABC'; // <p id="p-id">ABC</p>
// 设置HTML:
p.innerHTML = 'ABC <span style="color:red">RED</span> XYZ';
// <p>...</p>的内部结构已修改
用innerHTML时要注意,是否需要写入HTML。如果写入的字符串是通过网络拿到的,要注意对字符编码来避免XSS攻击。
第二种是修改innerText或textContent属性
当我们获得了某个DOM节点,想在这个DOM节点内插入新的DOM,应该如何做?
如果这个DOM节点是空的,例如,<div></div>,那么,直接使用innerHTML = '<span>child</span>'就可以修改DOM节点的内容,相当于“插入”了新的DOM节点。
如果这个DOM节点不是空的,那就不能这么做,因为innerHTML会直接替换掉原来的所有子节点。
有两个办法可以插入新的节点。一个是使用appendChild,把一个子节点添加到父节点的最后一个子节点。例如:
<!-- HTML结构 -->
<p id="js">JavaScript</p>
<div id="list">
<p id="java">Java</p>
<p id="python">Python</p>
<p id="scheme">Scheme</p>
</div>
把<p id="js">JavaScript</p>添加到<div id="list">的最后一项:
let
js = document.getElementById('js'),
list = document.getElementById('list');
list.appendChild(js);
如果我们要把子节点插入到指定的位置怎么办?可以使用parentElement.insertBefore(newElement, referenceElement);,子节点会插入到referenceElement之前
删除一个DOM节点就比插入要容易得多。
要删除一个节点,首先要获得该节点本身以及它的父节点,然后,调用父节点的removeChild把自己删掉:
// 拿到待删除节点:
let self = document.getElementById('to-be-removed');
// 拿到父节点:
let parent = self.parentElement;
// 删除:
let removed = parent.removeChild(self);
removed === self; // true
操作表单直接看https://liaoxuefeng.com/books/javascript/browser/form/index.html
AJAX
一、AJAX概述
AJAX是Asynchronous JavaScript and XML的缩写,即异步JavaScript和XML。它是一种在不重新加载整个页面的情况下,通过JavaScript和服务器进行数据交互和页面更新的技术。AJAX技术可以使得网页交互更加流畅和快速,同时也可以减少网络流量和服务器资源的占用。
在AJAX技术中,当用户执行某个操作时,例如点击按钮或输入数据,JavaScript代码会通过XMLHttpRequest对象向服务器发送异步请求,并接收服务器返回的数据。在接收到数据后,JavaScript代码可以对页面进行动态更新,例如更新部分页面内容、添加新的内容、或者执行特定的操作等。
二、XMLHttpRequest对象
XMLHttpRequest对象是AJAX技术的核心,它是一个内置对象,可以在JavaScript中使用。该对象可以通过JavaScript向服务器发送HTTP请求,并接收服务器返回的数据。以下是XMLHttpRequest对象的基本用法:
- 创建XMLHttpRequest对象
在JavaScript中,可以使用以下代码创建一个XMLHttpRequest对象:
“`javascript
let xhr = new XMLHttpRequest();
“`
- 发送HTTP请求
使用XMLHttpRequest对象发送HTTP请求的基本步骤如下:
- 调用open()方法,指定请求的方法、URL和是否使用异步方式。例如,以下代码指定了一个GET方法的请求,请求URL为”/api/data”,并使用异步方式发送请求:
“`javascript
xhr.open(“GET”, “/api/data”, true);
“`
- 添加请求头。可以使用setRequestHeader()方法添加请求头,例如:
“`javascript
xhr.setRequestHeader(“Content-Type”, “application/json”);
“`
- 发送请求。使用send()方法发送HTTP请求,例如:
“`javascript
xhr.send();
“`
3. 处理服务器响应
当服务器响应XMLHttpRequest对象的请求时,可以通过以下属性和方法来获取响应数据:
- responseText:响应的文本数据。
- responseXML:响应的XML数据。
- status:响应的状态码。
- statusText:响应状态码对应的文本信息。
- getAllResponseHeaders():获取所有响应头。
- getResponseHeader(header):获取指定响应头。
在接收到响应后,我们可以通过回调函数来处理响应数据。例如,以下代码定义了一个回调函数,当XMLHttpRequest对象接收到响应时,会调用该函数:
“`javascript
xhr.onload = function() {
if (xhr.status === 200) {
console.log(xhr.responseText);
} else {
console.log(“请求失败:” + xhr.statusText);
}
};
“`
如果不考虑早期浏览器的兼容性问题,现代浏览器还提供了原生支持的Fetch API,以Promise方式提供。使用Fetch API发送HTTP请求代码如下:
async function get(url) {
let resp = await fetch(url);
let result = await resp.text();
return result;
}
// 发送异步请求:
get(‘./content.html’).then(data => {
let textarea = document.getElementById(‘fetch-response-text’);
textarea.value = data;
});
CORS
CORS全称Cross-Origin Resource Sharing,是HTML5规范定义的如何跨域访问资源。
了解CORS前,我们先搞明白概念:
Origin表示本域,也就是浏览器当前页面的域。当JavaScript向外域(如sina.com)发起请求后,浏览器收到响应后,首先检查Access-Control-Allow-Origin是否包含本域,如果是,则此次跨域请求成功,如果不是,则请求失败,JavaScript将无法获取到响应的任何数据。
用一个图来表示就是:
GET /res/abc.data
Host: sina.com
┌──────┐ Origin: http://my.com ┌────────┐
│my.com│───────────────────────────────────▶│sina.com│
│ │◀───────────────────────────────────│ │
└──────┘ HTTP/1.1 200 OK └────────┘
Access-Control-Allow-Origin: http://my.com
Content-Type: text/xml
<xml data...>
假设本域是my.com,外域是sina.com,只要响应头Access-Control-Allow-Origin为http://my.com,或者是*,本次请求就可以成功。
可见,跨域能否成功,取决于对方服务器是否愿意给你设置一个正确的Access-Control-Allow-Origin,决定权始终在对方手中。
上面这种跨域请求,称之为“简单请求”。简单请求包括GET、HEAD和POST(POST的Content-Type类型 仅限application/x-www-form-urlencoded、multipart/form-data和text/plain),并且不能出现任何自定义头(例如,X-Custom: 12345),通常能满足90%的需求。
无论你是否需要用JavaScript通过CORS跨域请求资源,你都要了解CORS的原理。最新的浏览器全面支持HTML5。在引用外域资源时,除了JavaScript和CSS外,都要验证CORS。例如,当你引用了某个第三方CDN上的字体文件时:
/* CSS */
@font-face {
font-family: 'FontAwesome';
src: url('http://cdn.com/fonts/fontawesome.ttf') format('truetype');
}
如果该CDN服务商未正确设置Access-Control-Allow-Origin,那么浏览器无法加载字体资源。
对于PUT、DELETE以及其他类型如application/json的POST请求,在发送AJAX请求之前,浏览器会先发送一个OPTIONS请求(称为preflighted请求)到这个URL上,询问目标服务器是否接受:
OPTIONS /path/to/resource HTTP/1.1
Host: bar.com
Origin: http://my.com
Access-Control-Request-Method: POST
服务器必须响应并明确指出允许的Method:
HTTP/1.1 200 OK
Access-Control-Allow-Origin: http://my.com
Access-Control-Allow-Methods: POST, GET, PUT, OPTIONS
Access-Control-Max-Age: 86400
浏览器确认服务器响应的Access-Control-Allow-Methods头确实包含将要发送的AJAX请求的Method,才会继续发送AJAX,否则,抛出一个错误。
由于以POST、PUT方式传送JSON格式的数据在REST中很常见,所以要跨域正确处理POST和PUT请求,服务器端必须正确响应OPTIONS请求。
Promise
“承诺将来会执行”的对象在JavaScript中称为Promise对象。如下test是一个判断函数,用一个Promise对象来执行它,并在将来某个时刻获得成功或失败的结果:
let p1 = new Promise(test);
let p2 = p1.then(function (result) {
console.log('成功:' + result);
});
let p3 = p2.catch(function (reason) {
console.log('失败:' + reason);
});
变量p1是一个Promise对象,它负责执行test函数。由于test函数在内部是异步执行的,当test函数执行成功时,我们告诉Promise对象:
// 如果成功,执行这个函数:
p1.then(function (result) {
console.log('成功:' + result);
});
当test函数执行失败时,我们告诉Promise对象:
p2.catch(function (reason) {
console.log('失败:' + reason);
});
Promise对象可以串联起来,所以上述代码可以简化为:
new Promise(test).then(function (result) {
console.log('成功:' + result);
}).catch(function (reason) {
console.log('失败:' + reason);
});
一个Promise对象在操作网络时是异步的,等到返回后再调用回调函数,执行正确就调用then(),执行错误就调用catch(),虽然异步实现了,不会让用户感觉到页面“卡住”了,但是一堆then()、catch()写起来麻烦看起来也乱。
有没有更简单的写法?
可以用关键字async配合await调用Promise,实现异步操作,但代码却和同步写法类似:
async function get(url) {
let resp = await fetch(url);
let result = await resp.json();
return result;
}
使用async function可以定义一个异步函数,异步函数和Promise可以看作是等价的,在async function内部,用await调用另一个异步函数,写起来和同步代码没啥区别,但执行起来是异步的。
也就是说:
let resp = await fetch(url);
自动实现了异步调用,它和下面的Promise代码等价:
let promise = fetch(url);
promise.then((resp) => {
// 拿到resp
});
如果我们要实现catch()怎么办?用Promise的写法如下:
let promise = fetch(url);
promise.then((resp) => {
// 拿到resp
}).catch(e => {
// 出错了
});
用await调用时,直接用传统的try { ... } catch:
async function get(url) {
try {
let resp = await fetch(url);
let result = await resp.json();
return result;
} catch (e) {
// 出错了
}
}
用async定义异步函数,用await调用异步函数,写起来和同步代码差不多,但可读性大大提高
Canvas是HTML5新增的组件,它就像一块幕布,可以用JavaScript在上面绘制各种图表、动画等。
一个Canvas定义了一个指定尺寸的矩形框,在这个范围内我们可以随意绘制:
<canvas id="test-canvas" width="300" height="200"></canvas>
getContext('2d')方法让我们拿到一个CanvasRenderingContext2D对象,所有的绘图操作都需要通过这个对象完成。
let ctx = canvas.getContext('2d');
如果需要绘制3D怎么办?HTML5还有一个WebGL规范,允许在Canvas中绘制3D图形:
gl = canvas.getContext("webgl")
前端库jQuery简介
jQuery能帮我们干这些事情:
- 消除浏览器差异:你不需要自己写冗长的代码来针对不同的浏览器来绑定事件,编写AJAX等代码;
- 简洁的操作DOM的方法:写
$('#test')肯定比document.getElementById('test')来得简洁;
- 轻松实现动画、修改CSS等各种操作。
只需要在页面的<head>引入jQuery文件即可就可使用 <script src=”https://code.jquery.com/jquery-3.7.1.min.js”></script>
$是著名的jQuery符号。实际上,jQuery把所有功能全部封装在一个全局变量jQuery中,
如果某个DOM节点有id属性,利用jQuery查找如下:
// 查找<div id="abc">:
let div = $('#abc');
注意,#abc以#开头。返回的对象是jQuery对象。
什么是jQuery对象?jQuery对象类似数组,它的每个元素都是一个引用了DOM节点的对象。
以上面的查找为例,如果id为abc的<div>存在,返回的jQuery对象如下:
[<div id="abc">...</div>]
按tag查找只需要写上tag名称就可以了:
let ps = $('p'); // 返回所有<p>节点
ps.length; // 数一数页面有多少个<p>节点
按class查找注意在class名称前加一个.:
let a = $('.red'); // 所有节点包含`class="red"`都将返回
// 例如:
// <div class="red">...</div>
// <p class="green red">...</p>
通常很多节点有多个class,我们可以查找同时包含red和green的节点:
let a = $('.red.green'); // 注意没有空格!
// 符合条件的节点:
// <div class="red green">...</div>
// <div class="blue green red">...</div>
很多时候按属性查找会非常方便,比如在一个表单中按属性来查找:
let email = $('[name=email]'); // 找出<??? name="email">
let passwordInput = $('[type=password]'); // 找出<??? type="password">
let a = $('[items="A B"]'); // 找出<??? items="A B">
添加新的DOM节点,除了通过jQuery的html()这种暴力方法外,还可以用append()方法,例如:
<div id="test-div">
<ul>
<li><span>JavaScript</span></li>
<li><span>Python</span></li>
<li><span>Swift</span></li>
</ul>
</div>
如何向列表新增一个语言?首先要拿到<ul>节点:
let ul = $('#test-div>ul');
然后,调用append()传入HTML片段:
ul.append('<li><span>Haskell</span></li>');
浏览器在接收到用户的鼠标或键盘输入后,会自动在对应的DOM节点上触发相应的事件。如果该节点已经绑定了对应的JavaScript处理函数,该函数就会自动调用。
由于不同的浏览器绑定事件的代码都不太一样,所以用jQuery来写代码,就屏蔽了不同浏览器的差异,我们总是编写相同的代码。
举个例子,假设要在用户点击了超链接时弹出提示框,我们用jQuery这样绑定一个click事件
// 获取超链接的jQuery对象:
let a = $('#test-link');
a.click(function () {
alert('Hello!');
});
jQuery能够绑定的事件主要包括:
鼠标事件
- click: 鼠标单击时触发;
- dblclick:鼠标双击时触发;
- mouseenter:鼠标进入时触发;
- mouseleave:鼠标移出时触发;
- mousemove:鼠标在DOM内部移动时触发;
- hover:鼠标进入和退出时触发两个函数,相当于mouseenter加上mouseleave。
键盘事件
键盘事件仅作用在当前焦点的DOM上,通常是<input>和<textarea>。
- keydown:键盘按下时触发;
- keyup:键盘松开时触发;
- keypress:按一次键后触发。
其他事件
- focus:当DOM获得焦点时触发;
- blur:当DOM失去焦点时触发;
- change:当
<input>、<select>或<textarea>的内容改变时触发;
- submit:当
<form>提交时触发;
- ready:当页面被载入并且DOM树完成初始化后触发。
其中,ready仅作用于document对象。由于ready事件在DOM完成初始化后触发,且只触发一次
jQuery内置了几种动画样式:
如直接以无参数形式调用show()和hide(),会显示和隐藏DOM元素。但是,只要传递一个时间参数进去,就变成了动画:
let div = $('#test-show-hide');
div.hide(3000); // 在3秒钟内逐渐消失