Bag of Words(BoW)又称词袋模型,是一种简单而有效的文本向量化方法。词袋模型目前没有归属一个具体的发明者,而是在信息检索、文本分类和自然语言处理等领域中逐渐发展演变出来的一种常用的文本表示方法。One-Hot编码虽然完成了数据从非数值到数值的转变,但在文本分类,特征提取等方面作用十分有限,且每个词都对应一个稀疏向量,存储效率较低。词袋模型将文本看作是单词的无序集合,忽略词的顺序和语法,只关注词的出现频率。因此词袋模型在One-Hot编码的基础上提升了文本向量化的效果,并减少了存储负担。
Word2Vec主要由两种模型架构组成:Skip-Gram和Continuous Bag of Words(CBOW)。Skip-Gram通过当前词预测其上下文词。给定一个中心词,模型会预测一个固定长度的上下文窗口(前后若干词)中的所有词。训练过程中,模型会学习到每个词的向量表示,使得能够更好地预测这些上下文词。与Skip-Gram相反,CBOW的目标是通过上下文词预测当前词。给定一个上下文窗口中的所有词,模型会预测这个窗口的中心词。
Word2Vec模型的核心思想是通过训练神经网络,使得单词与其上下文之间的关系可以在向量空间中被有效地表示。Word2Vec的输入层是一个one-hot向量(one-hot vector),长度为词汇表大小(V)。紧接着是一个投影层,由输入层经过一个权重矩阵W(维度为V x N,N为嵌入向量的维度),投影到N维向量空间中。投影层的输出通过另一个权重矩阵W’(维度为N x V),映射回一个词汇表大小的向量,此为输出层。最后经过一个Softmax层得到每个词的概率。在训练过程中,Word2Vec模型通过最大化目标函数(取决于使用Skip-Gram还是CBOW,以及采用的优化函数的方法)来更新权重矩阵,从而使得embedding能够捕捉到词汇的语义信息。
优点:
● 由于采用了浅层神经网络,训练速度较快,适合处理大规模数据。
● 能够捕捉到词与词之间的语义关系,如词性、同义词等。
● 可以用于多种自然语言处理任务,如文本分类、情感分析、机器翻译等。
缺点:
● 每个词只有一个固定的向量表示,无法处理多义词的不同语义。
● 无法考虑词在不同上下文中的语义变化。
应用场景:
● 信息检索
● 文本分类
● 推荐系统,如根据用户的评论调整推荐的产品
GloVe(出现于2014年)
GloVe (Global Vectors for Word Representation)是一种无监督的文本向量化的学习算法,由斯坦福大学的Jeffrey Pennington等在2014年提出。它通过捕捉单词在大规模语料库中的共现统计信息,生成高质量的词向量。GloVe的作者认为使用共现词的概率的比可以更好地区分相关和无关的词,因此GloVe的核心是共现矩阵和词对共现概率。共现矩阵中的每个元素Xi,j表示词j出现在词i的上下文中的次数。词对共现概率定义为:
ELMo(Embeddings from Language Models)是一种由Allen Institute for AI的研究者Matthew E. Peters等在2018年提出的embedding方法,通过上下文中的词语来捕捉语义。ELMo的作者认为之前的文本向量化方式没有考虑一个词在不同上下文中意义的变化,所以与Word2Vec和GloVe不同,ELMo能够捕捉到词在不同上下文中的不同意义,从而生成更为丰富和精确的embedding。
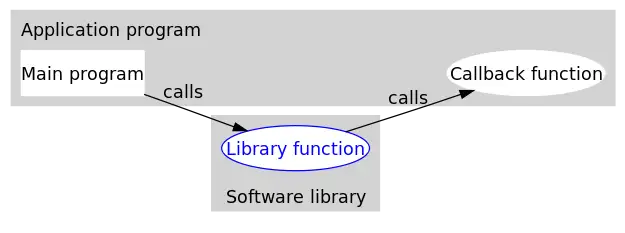
打个比方,有一家旅馆提供叫醒服务,但是要求旅客自己决定叫醒的方法。可以是打客房电话,也可以是派服务员去敲门,睡得死怕耽误事的,还可以要求往自己头上浇盆水。这里,“叫醒”这个行为是旅馆提供的,相当于库函数,但是叫醒的方式是由旅客决定并告诉旅馆的,也就是回调函数。而旅客告诉旅馆怎么叫醒自己的动作,也就是把回调函数传入库函数的动作,称为登记回调函数(to register a callback function)。如下图所示(图片来源:维基百科):
之所以特意强调这个第三方,是因为我在网上读相关文章时得到一种印象,很多人把它简单地理解为两个个体之间的来回调用。譬如,很多中文网页在解释“回调”(callback)时,都会提到这么一句话:“If you call me, I will call you back.”我没有查到这句英文的出处。我个人揣测,很多人把起始函数和回调函数看作为一体,大概有两个原因:第一,可能是“回调”这一名字的误导;第二,给中间函数传入什么样的回调函数,是在起始函数里决定的。实际上,回调并不是“你我”两方的互动,而是ABC的三方联动。有了这个清楚的概念,在自己的代码里实现回调时才不容易混淆出错。
Usage: uvicorn [OPTIONS] APP
Options:
--host TEXT Bind socket to this host. [default:
127.0.0.1]
--port INTEGER Bind socket to this port. [default: 8000]
--uds TEXT Bind to a UNIX domain socket.
--fd INTEGER Bind to socket from this file descriptor.
--reload Enable auto-reload.
--reload-dir TEXT Set reload directories explicitly, instead
of using the current working directory.
--workers INTEGER Number of worker processes. Defaults to the
$WEB_CONCURRENCY environment variable if
available. Not valid with --reload.
--loop [auto|asyncio|uvloop|iocp]
Event loop implementation. [default: auto]
--http [auto|h11|httptools] HTTP protocol implementation. [default:
auto]
--ws [auto|none|websockets|wsproto]
WebSocket protocol implementation.
[default: auto]
--lifespan [auto|on|off] Lifespan implementation. [default: auto]
--interface [auto|asgi3|asgi2|wsgi]
Select ASGI3, ASGI2, or WSGI as the
application interface. [default: auto]
--env-file PATH Environment configuration file.
--log-config PATH Logging configuration file.
--log-level [critical|error|warning|info|debug|trace]
Log level. [default: info]
--access-log / --no-access-log Enable/Disable access log.
--use-colors / --no-use-colors Enable/Disable colorized logging.
--proxy-headers / --no-proxy-headers
Enable/Disable X-Forwarded-Proto,
X-Forwarded-For, X-Forwarded-Port to
populate remote address info.
--forwarded-allow-ips TEXT Comma separated list of IPs to trust with
proxy headers. Defaults to the
$FORWARDED_ALLOW_IPS environment variable if
available, or '127.0.0.1'.
--root-path TEXT Set the ASGI 'root_path' for applications
submounted below a given URL path.
--limit-concurrency INTEGER Maximum number of concurrent connections or
tasks to allow, before issuing HTTP 503
responses.
--backlog INTEGER Maximum number of connections to hold in
backlog
--limit-max-requests INTEGER Maximum number of requests to service before
terminating the process.
--timeout-keep-alive INTEGER Close Keep-Alive connections if no new data
is received within this timeout. [default:
5]
--ssl-keyfile TEXT SSL key file
--ssl-certfile TEXT SSL certificate file
--ssl-version INTEGER SSL version to use (see stdlib ssl module's)
[default: 2]
--ssl-cert-reqs INTEGER Whether client certificate is required (see
stdlib ssl module's) [default: 0]
--ssl-ca-certs TEXT CA certificates file
--ssl-ciphers TEXT Ciphers to use (see stdlib ssl module's)
[default: TLSv1]
--header TEXT Specify custom default HTTP response headers
as a Name:Value pair
--help Show this message and exit.