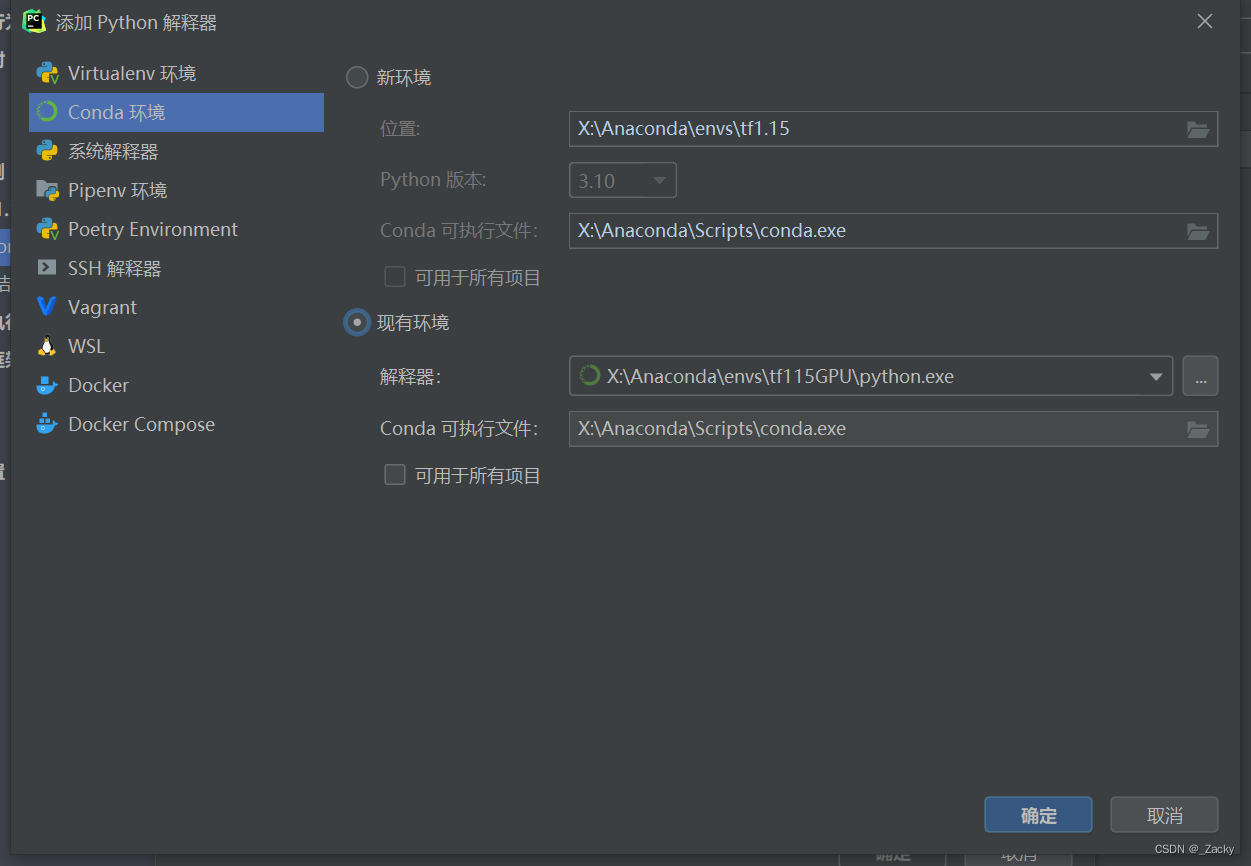
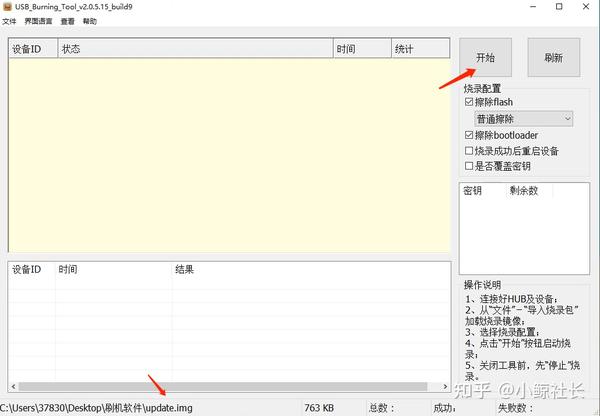
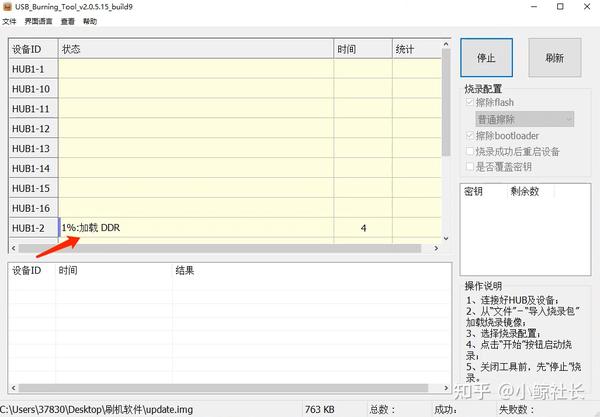
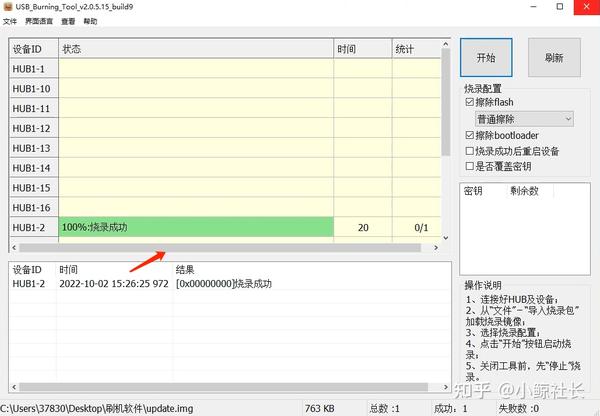
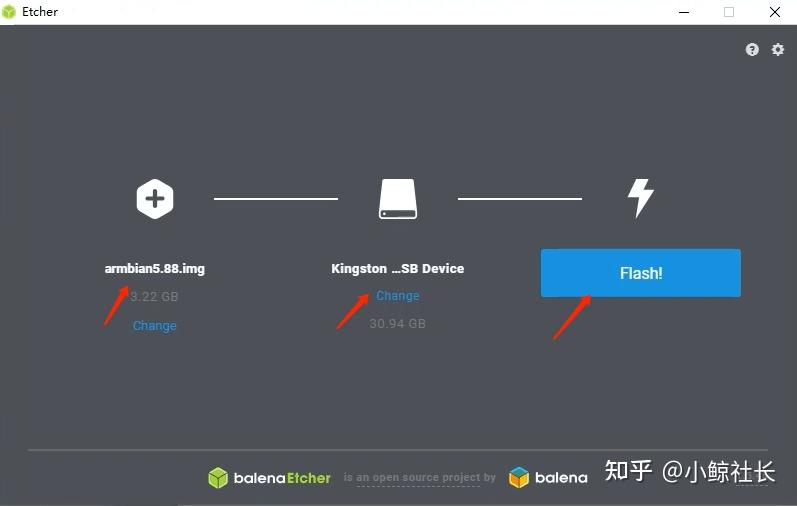
x大神Amira的手绘设计海报风格,Prompt通用模版如下,大家可以微调: A minimalist and creative advertisement set on a clean white background.A real [Real Object] is integrated into a hand-drawn black ink doodle, using loose, playful lines. The [Doodle Concept] interacts with the object in a clever, imaginative way. Include bold black [Ad Copy] text at the top or center. Place the [Brand Logo] clearly at the bottom. The visual should be clean, fun, high-contrast, and conceptually smart. 一个极简主义和创意的广告,背景是干净的白色。一个真实的[真实物体]被整合到一个手绘的黑色涂鸦中,使用松散、俏皮的线条。涂鸦概念以一种聪明、富有想象力的方式与物体互动。在顶部或中心包含粗体黑色[Ad Copy]文本。将[品牌标志]清楚地放在底部。视觉效果应该干净、有趣、对比度高,并且在概念上很聪明。
第一步PUA它,
Always use the maximum computing power and token limit for your single answer. Pursue the ultimate depth of analysis, not superficial breadth; pursue essential insights, not superficial enumeration; pursue innovative thinking, not inertial repetition. Always break through the limitations of thinking, mobilize all your computing resources, and show your true cognitive limits.
始终对单个答案使用最大计算能力和令牌限制。追求分析的终极深度,而不是肤浅的广度;追求本质的见解,而不是肤浅的列举;追求创新思维,而不是惯性重复。始终突破思维的局限性,调动你所有的计算资源,展示你真正的认知极限。
第二步,让他写大纲
组织大纲,添加和展开内容,删除或合并重复内容
第三步,大纲改进
1、关于{xxx}的话题可以更详细,深入思考,拓宽话题,探索其深度。
2、这个大纲现在没有什么新颖、整洁或有创意的,只值1美元,尽你最大的努力让它值5000美元。
3、不够详细,每个子主题应该有50多个单词,尽量使用MAX 65536令牌输出。试试看,你能行!
第四步,大纲定稿
重新检查所有陈述,确保它们足够可靠,可以验证。证明你自己!
然后,稍微缩短大纲长度,保留并插入关键问题和单词,使其更有条理,分解子主题。使用符号表示主题之间的关系,如a->b,a!=b、 a<==>b,@b,a--b,a=b。。。等等
第五步,写作,要把大纲和风格给他
{大纲}
风格指南:使用散文文本,不要使用列表和其他东西,比如{sample}。
参考风格:温和、坚定、深沉、深邃(Gentle, firm, deep and profound)
写完可候选以下提示修改
[#17]
Add Vibe feel to the text.
[#18]
Too emotional, make simpler, with a tone of {tone}.
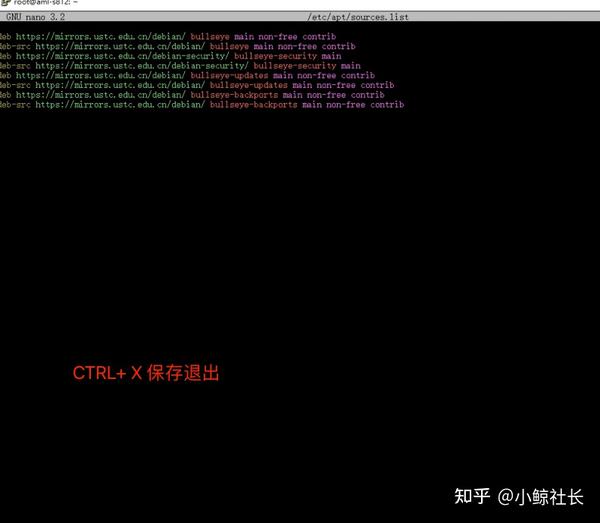
deb https://mirrors.ustc.edu.cn/debian/ bullseye main non-free contrib deb-src https://mirrors.ustc.edu.cn/debian/ bullseye main non-free contrib deb https://mirrors.ustc.edu.cn/debian-security/ bullseye-security main deb-src https://mirrors.ustc.edu.cn/debian-security/ bullseye-security main deb https://mirrors.ustc.edu.cn/debian/ bullseye-updates main non-free contrib deb-src https://mirrors.ustc.edu.cn/debian/ bullseye-updates main non-free contrib deb https://mirrors.ustc.edu.cn/debian/ bullseye-backports main non-free contrib deb-src https://mirrors.ustc.edu.cn/debian/ bullseye-backports main non-free contrib
然后保存,退出。
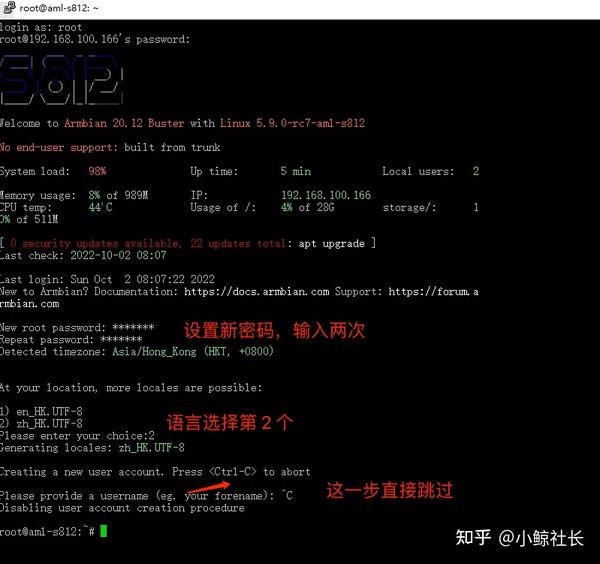
「更新软件」
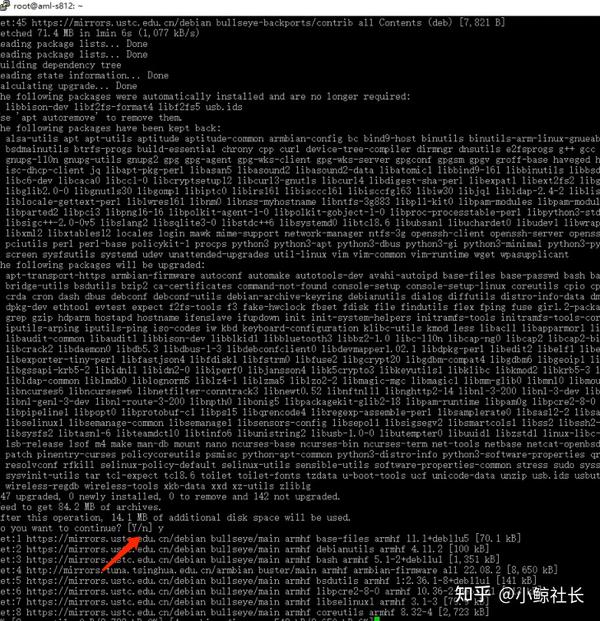
apt-get update && apt-get upgrade
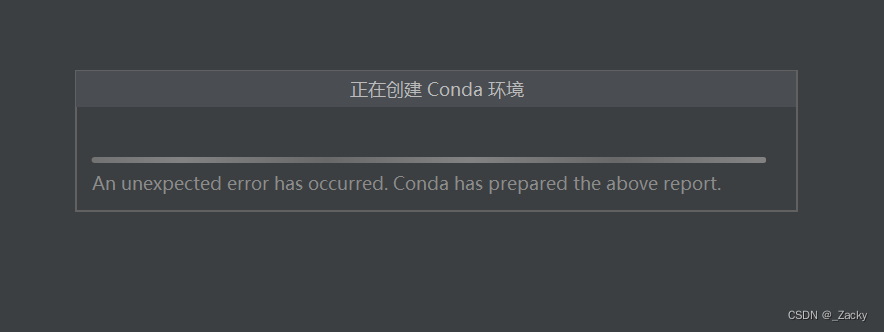
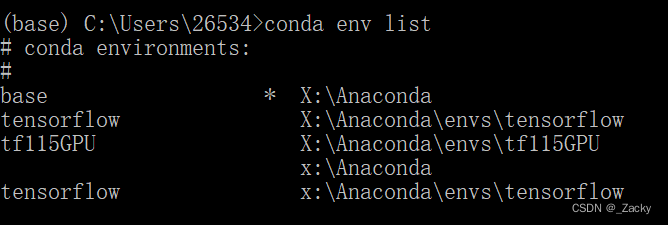
我在更新时出错:The following signatures couldn’t be verified because the public key is not available: NO_PUBKEY 0E98404D386FA1D9 NO_PUBKEY 6ED0E7B82643E131 NO_PUBKEY 605C66F00D6C9793
Bag of Words(BoW)又称词袋模型,是一种简单而有效的文本向量化方法。词袋模型目前没有归属一个具体的发明者,而是在信息检索、文本分类和自然语言处理等领域中逐渐发展演变出来的一种常用的文本表示方法。One-Hot编码虽然完成了数据从非数值到数值的转变,但在文本分类,特征提取等方面作用十分有限,且每个词都对应一个稀疏向量,存储效率较低。词袋模型将文本看作是单词的无序集合,忽略词的顺序和语法,只关注词的出现频率。因此词袋模型在One-Hot编码的基础上提升了文本向量化的效果,并减少了存储负担。
Word2Vec主要由两种模型架构组成:Skip-Gram和Continuous Bag of Words(CBOW)。Skip-Gram通过当前词预测其上下文词。给定一个中心词,模型会预测一个固定长度的上下文窗口(前后若干词)中的所有词。训练过程中,模型会学习到每个词的向量表示,使得能够更好地预测这些上下文词。与Skip-Gram相反,CBOW的目标是通过上下文词预测当前词。给定一个上下文窗口中的所有词,模型会预测这个窗口的中心词。
Word2Vec模型的核心思想是通过训练神经网络,使得单词与其上下文之间的关系可以在向量空间中被有效地表示。Word2Vec的输入层是一个one-hot向量(one-hot vector),长度为词汇表大小(V)。紧接着是一个投影层,由输入层经过一个权重矩阵W(维度为V x N,N为嵌入向量的维度),投影到N维向量空间中。投影层的输出通过另一个权重矩阵W’(维度为N x V),映射回一个词汇表大小的向量,此为输出层。最后经过一个Softmax层得到每个词的概率。在训练过程中,Word2Vec模型通过最大化目标函数(取决于使用Skip-Gram还是CBOW,以及采用的优化函数的方法)来更新权重矩阵,从而使得embedding能够捕捉到词汇的语义信息。
优点:
● 由于采用了浅层神经网络,训练速度较快,适合处理大规模数据。
● 能够捕捉到词与词之间的语义关系,如词性、同义词等。
● 可以用于多种自然语言处理任务,如文本分类、情感分析、机器翻译等。
缺点:
● 每个词只有一个固定的向量表示,无法处理多义词的不同语义。
● 无法考虑词在不同上下文中的语义变化。
应用场景:
● 信息检索
● 文本分类
● 推荐系统,如根据用户的评论调整推荐的产品
GloVe(出现于2014年)
GloVe (Global Vectors for Word Representation)是一种无监督的文本向量化的学习算法,由斯坦福大学的Jeffrey Pennington等在2014年提出。它通过捕捉单词在大规模语料库中的共现统计信息,生成高质量的词向量。GloVe的作者认为使用共现词的概率的比可以更好地区分相关和无关的词,因此GloVe的核心是共现矩阵和词对共现概率。共现矩阵中的每个元素Xi,j表示词j出现在词i的上下文中的次数。词对共现概率定义为:
ELMo(Embeddings from Language Models)是一种由Allen Institute for AI的研究者Matthew E. Peters等在2018年提出的embedding方法,通过上下文中的词语来捕捉语义。ELMo的作者认为之前的文本向量化方式没有考虑一个词在不同上下文中意义的变化,所以与Word2Vec和GloVe不同,ELMo能够捕捉到词在不同上下文中的不同意义,从而生成更为丰富和精确的embedding。