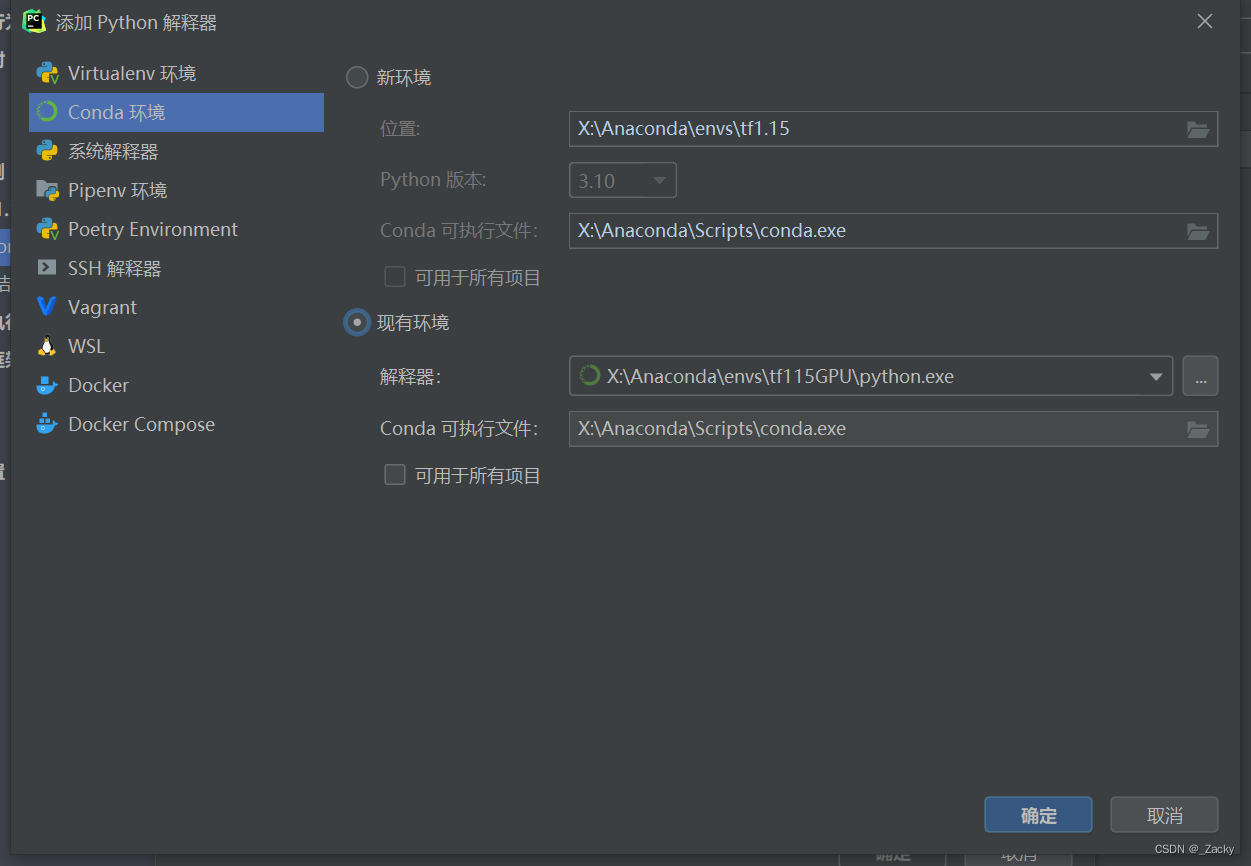
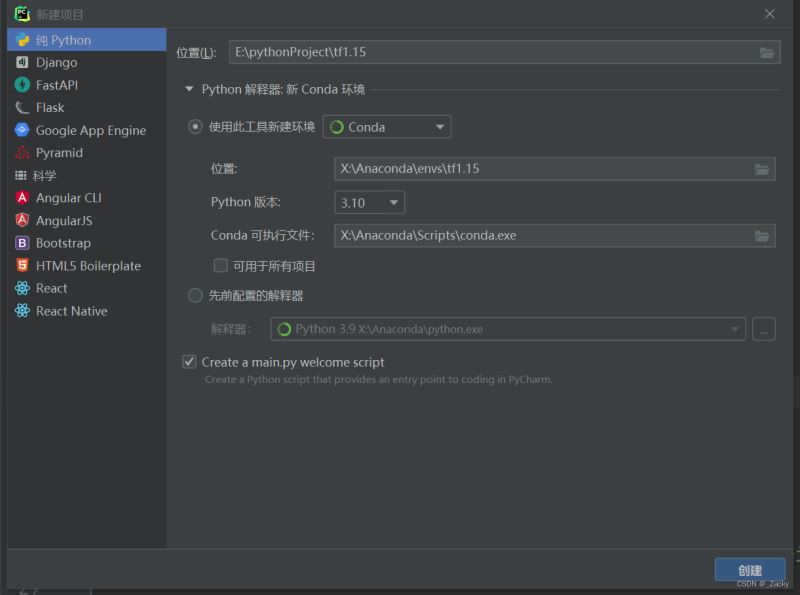
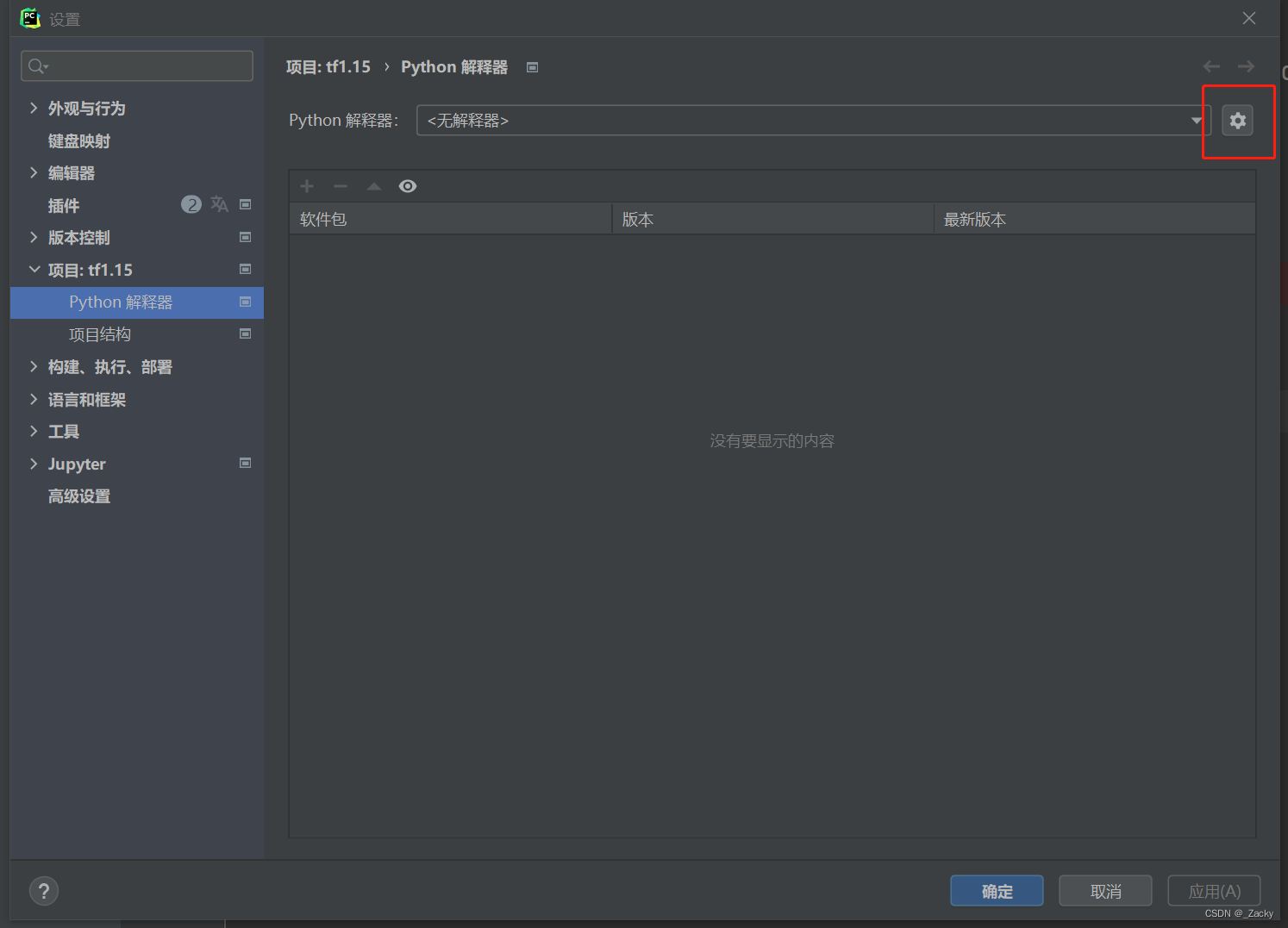
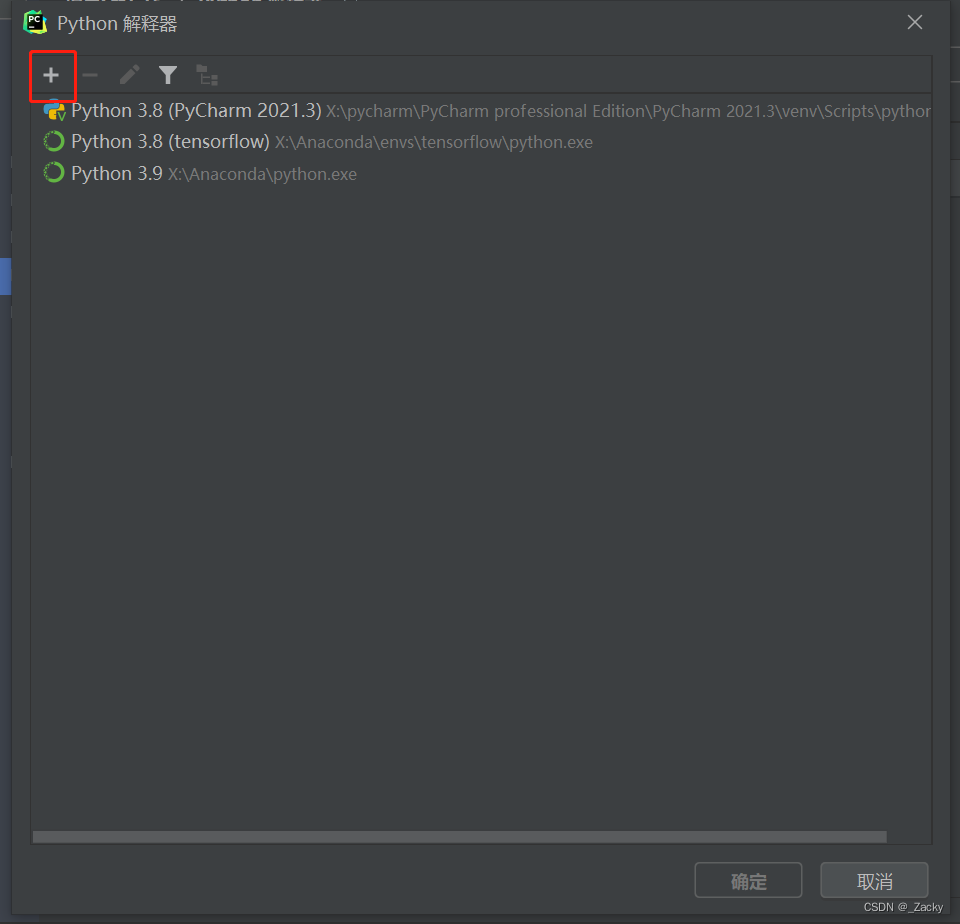
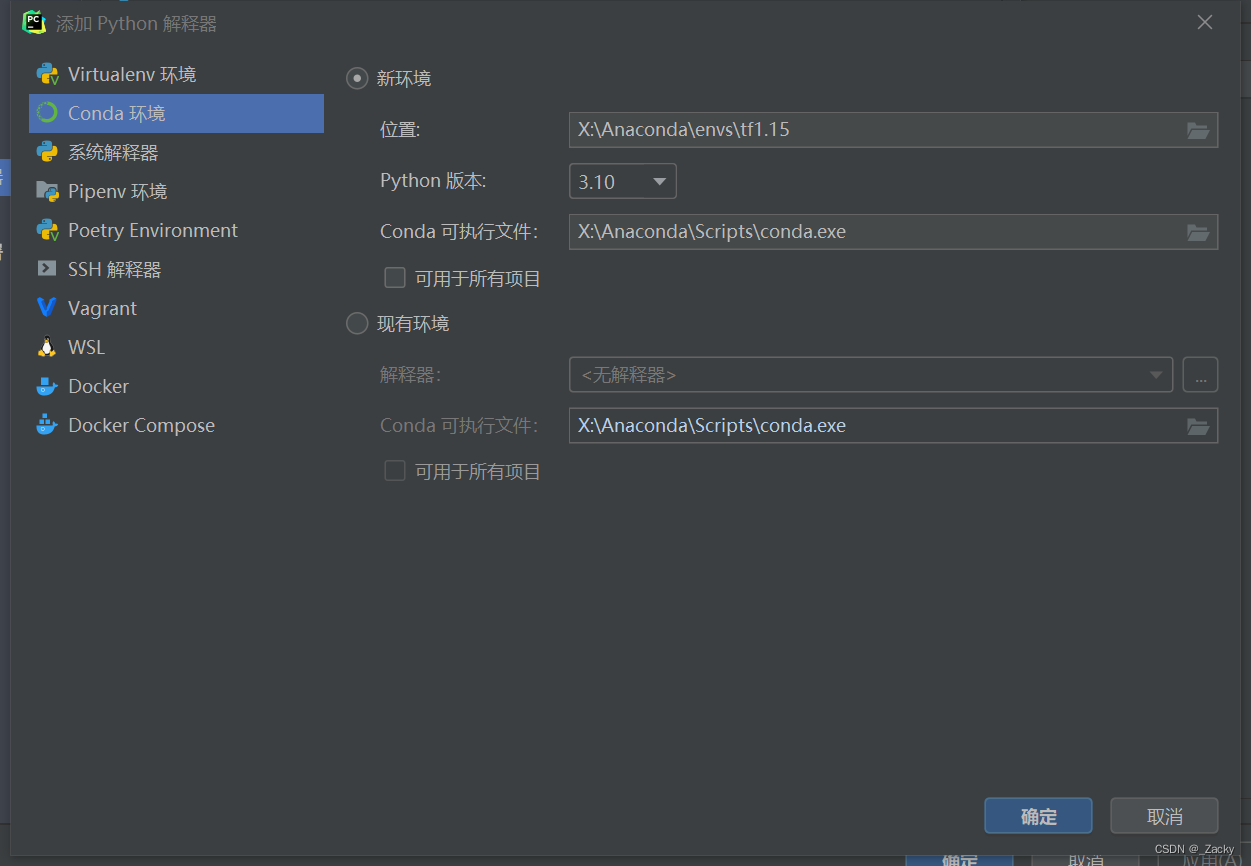
组合:在一个类的属性中调用了另一个类,将另一个类的对象作为数据属性,称为类的组合。
这种组合使用的好处在于,它允许你将复杂的功能分解为更小、更易于管理的部分。每个类可以专注于自己的职责,从而提高代码的可读性和可维护性。
这种模式允许你创建一个对象,这个对象可以与创建它的对象进行交互。这是一种常见的设计模式,特别是在复杂的软件系统中,它允许你将不同的功能组织成不同的类,同时保持这些类之间的协作和通信。
简单来说,这种初始化方式是说:“我(当前类的实例)需要一个组件,所以我创建了一个实例,并且把我自己(self)作为参数传给了它,这样它就可以使用我的功能和数据了。”
再来一个例子
# 1、组合实例
class Ojb_1:
'''假设Ojb_1是一个装备库类,func_name是其中一件装备,装备后加1000战力。'''
def __init__(self, agg):
self.agg = agg
def func_name(self):
self.agg += 1000 # 在本身的战力上+1000
return self.agg # 返回最终战力
class Ojb_2:
'''假设Ojb_2是一个角色类,每个角色都有名称等信息'''
def __init__(self, name, agg):
self.name = name # 角色名称
self.agg = agg # 本身的战力
self.Ojb_1 = Ojb_1(self.agg) # 重点在这里,将该人物原来的战力传到装备库类,把自己作为参数传给ojb_1的这个实例,这样他能使用自己的数据
if __name__ == '__main__':
'''假设广深小龙原来战力=500'''
r1 = Ojb_2('广深小龙', 500)
res = r1.Ojb_1.func_name()
print(res)
①Ojb_1是装备库类,func_name是一件装备,人物装备后会增加1000的战力,self.agg=原人物的战力
②Ojb_2是角色类,有角色的名称与原角色的战力等信息,self.Ojb_1是将原人物的战力先传至装备库,只要人物调用装备了func_name就会在原战力基础上增加1000–
下面来一个完整的例子:
class ResearchConductor:
def __init__(self, researcher):
self.researcher = researcher
async def conduct_research(self):
# 这里使用 researcher 对象的属性和方法来执行研究
print(f"Starting research on: {self.researcher.query}")
# 假设这里进行了一些异步研究操作
# 返回研究结果
return f"Research results for {self.researcher.query}"
class ContextManager:
def __init__(self, researcher):
self.researcher = researcher
async def get_context(self):
# 获取研究上下文的逻辑
return "Context for research"
class ReportGenerator:
def __init__(self, researcher):
self.researcher = researcher
async def generate_report(self, context):
# 生成报告的逻辑
return f"Report based on context: {context}"
class Researcher:
def __init__(self, query, config):
self.query = query
self.config = config
self.research_conductor = ResearchConductor(self) # 组合使用 ResearchConductor
self.context_manager = ContextManager(self) # 组合使用 ContextManager
self.report_generator = ReportGenerator(self) # 组合使用 ReportGenerator
async def perform_research(self):
# 执行研究流程
context = await self.context_manager.get_context() # 从 ContextManager 获取上下文
research_results = await self.research_conductor.conduct_research() # 从 ResearchConductor 获取研究结果
report = await self.report_generator.generate_report(research_results) # 从 ReportGenerator 生成报告
return report
# 假设这是主程序
import asyncio
async def main():
# 创建 Researcher 实例
researcher = Researcher(query="How to learn Python", config={"setting": "value"})
# 执行研究并生成报告
report = await researcher.perform_research()
print(report)
# 运行主程序
asyncio.run(main())在这个例子中:
Researcher类是主类,它代表了一个研究者,拥有查询和配置。ResearchConductor类是Researcher的一个组件,负责执行研究任务。ContextManager类是另一个组件,负责获取研究的上下文。ReportGenerator类是第三个组件,负责基于研究结果生成报告。
每个组件都接收一个 researcher 对象作为参数,并在它们的构造函数中保存这个引用。这样,每个组件都可以访问主 Researcher 实例的属性和方法。
Researcher 类中的 perform_research 方法展示了如何使用这些组件来执行一个完整的研究流程:获取上下文、进行研究、生成报告。
最后,main 函数创建了一个 Researcher 实例,并调用 perform_research 方法来执行研究流程,并打印出生成的报告。这个例子展示了类的组合如何在实际的异步编程中被用来构建模块化的系统。
理解初始化 def __init__(self, researcher):
self.researcher = researcher 你将 self(即当前 Researcher 实例的引用)传递给 ResearchConductor 的构造函数。这意味着 ResearchConductor 类需要一个参数来初始化,这个参数是 Researcher 的一个实例。在 ResearchConductor 类中,这个参数被赋值给 self.researcher,所以,当你在 Researcher 类中创建 ResearchConductor 的实例时,你是在告诉 ResearchConductor:“嘿,这个 Researcher 实例是你的 researcher 对象。”这样,ResearchConductor 类就可以通过 self.researcher 访问 Researcher 实例的所有属性和方法
再来一个例子
class Engine:
"""这是一个简单的引擎类"""
def __init__(self, power):
self.power = power
def start(self):
print(f"引擎启动,功率:{self.power}")
class Car:
"""这是一个简单的汽车类,它组合了Engine类"""
def __init__(self, make, model, engine):
self.make = make
self.model = model
self.engine = engine # 引擎作为Car类的一个属性
def start_car(self):
self.engine.start() # 使用Engine类的start方法
print(f"汽车 {self.make} {self.model} 启动了。")
# 创建一个Engine实例
engine = Engine(200)
# 创建一个Car实例,并使用上面创建的Engine实例
car = Car("Ford", "Mustang", engine)
# 启动汽车
car.start_car()
在这个例子中,Engine 类定义了一个引擎的基本属性和方法。Car 类则通过将 Engine 实例作为其属性来组合 Engine 类,从而拥有启动汽车所需的功能。当你创建一个 Car 实例并调用 start_car 方法时,它将使用内部 Engine 实例的 start 方法来输出引擎启动的信息。–