TXGLJ使用netflow监控网络流量
按各地的ISP如各大运营商是要把流量发到TXGLJ进行JK的,具体手段就是运营商的交换机上配置netflow把监控的流量采集发送到TXGLJ要求的IP上,然后TXGLJ就可以进行流量分析了。 .交换机上配置下面归纳一下实施流量监控的步骤(以 Cisco 6000 系列交换机为例) : 1 )在 Cisco 6509 上配置 NetFlow (或其他网络设备),并输出到指定到 ossim 采集器( lp )的固定 UDP 端口。 2 )采集器软件为 ossim 系统的 F10W 一 tooll 具,该软件监听 UDP 端口,接收进入的 NetFlow 数据包并存储为特定格式。 3 )使用 Nfsen 等软件包中的工具对 NetFlow 源文件进行读取,转换成可读的 AS 1 Cll 格式,再用 ossim 内的 Perl 程序对 NetFlow 进行分析和规范格式的操作,并将读取的 NetFlow 信息存储入 Ossim 数据库中。 4 )依据蠕虫和。。 05 攻击等异常报文的流量特征,在分析程序中预设各种触发条件,定时运行,从中发现满足这些条件的「 low 。 5 )将分析结果在 Web 客户端中展示,或者通过 如果设奋不支持 Nettlow ,怎么对流量进行检测呢?对于这样的环境也有相应的解决方法,那就是使用 Fprobe 。利用 Fprobe 来生成 Netflow 报文,其默认格式为 VS 版本。最初「 probe 是一款在 BSO 环境下运行的软件,目前在 UNIX / Linux 平台上均可运行。它可以将 NIC 接口收到的数据转化为 Netflow 数据,并发送至 Netflow 分析端。我们可以通过部署这样一台 Ossim 服务器,将网络流量镜像至 Ossim 服务器,实现网络流量分析。 Ossim 服务器中的 Netflow 分析器,由下列三个工具组成:1 Fprobe :从远程主机发送数据流;2 Nfsen : NetFlow 的分析图形前端;3 Nfdump : NetFlow 采集模块;有关 Ossim 结构大家可以先参看本书第 14 章,这里介绍 Netflow 分析数据包的过程。首先,在网络接口接收网络数据,然后由「 probe 程序将收集的数据按照一定规则和格式进行转换 ( Netflow 格式),再发到系统的 555 端口(查看/ etc / d efa u It / fp 「 0 be 能得知详情),再由 Nfsen 系统中的 Nfdump 程序将转换后的数据统计
钉钉打卡手机定位模拟
下载“模拟定位助手”
进开发人员选项-选择模拟位置信息应用-
然后打开“ 模拟定位助手 ”在一个地方新建一个位置(最好多存几个地址,以便每次不同地址),下次按这个位置的播放键再打开钉钉就可以打卡时定位在这个位置,
有时钉钉会提示异常,这时最好不是继续打卡了,要不公司后台会有显示
华为EPON OLT开局配置
配置思路:1. 登录olt(console进去之后配地址)2.配置上联口(配vlan和起三层地址互联路由的lan口)3.epon接分光器,分光器下接光猫4.自动发现光猫、配置DBA数据和线路模板5.注册光猫6.提交保存。 在 MA5680T上配置:
telnet到MA5680T
>>User name:root
>>User password:admin
MA5680T>enable
MA5680T#config
MA5680T(config)#sysname Ueusiuee_MA5680T //修改系统名,根据实际设备修改
Ueusiuee_MA5680T(config)# time 2010-07-15 09:00:11 //修改系统时间
Ueusiuee_MA5680T(config)# switch language-mode //切换中文模式
当前语言模式已切换到本地语种
Ueusiuee_MA5680T(config)#display board 0 //查看所有单板状态
Ueusiuee_MA5680T(config)#board confirm 0 //确认所有单板
BaiZiMen_MA5680T(config)#interface epon 0/1
BaiZiMen_MA5680T(config-if-epon-0/1)#port 0 ont-auto-find enable //开启0端口的自动发现
BaiZiMen_MA5680T(config-if-epon-0/1)#port 1 ont-auto-find enable //开启1端口的自动发现
BaiZiMen_MA5680T(config-if-epon-0/1)#display ont autofind 0 //查看0端口发现的onu
Ueusiuee_MA5680T(config)#vlan 39 smart //创建网管vlan 39 类型为smart
Ueusiuee_MA5680T(config)#port vlan 39 0/18 0 //透传vlan 到上行口
Ueusiuee_MA5680T(config)# vlan 2064 to 2095 smart //创建从vlan号2094到2095的smart类型的宽带业务vlan
Ueusiuee_MA5680T(config)# vlan 3304 smart //创建窄带语音vlan
Ueusiuee_MA5680T(config)# port vlan 3304 0/18 0 //透传窄带语音vlan
Ueusiuee_MA5680T(config)# port vlan 2064 to 2095 0/18 0
Ueusiuee_MA5680T(config)#interface vlanif 39
Ueusiuee_MA5680T(config-vlanif39)# ip address 192.18.33.125 255.255.255.0 //配置网管地址
Ueusiuee_MA5680T(config)#quit
Ueusiuee_MA5680T(config)#ip route-static 0.0.0.0 0.0.0.0 192.18.33.254 //配置默认路由,172.18.33.254为网关
配置DBA模板和线路模板:
BaiZiMen_MA5680T(config)#display DBA-profile all //查看所有创建过的dba模板
BaiZiMen_MA5680T(config)#DBA-profile add profile-id 13 profile-name MA5616 type3 assure 102400 max 15360 // 创建模板id为13; 模板名为MA5616;
Assure: 保证带宽10M ; max:最大带宽15M;
BaiZiMen_MA5680T(config)#display ont-lineprofile epon all //查看所有创建过的线路模板
BaiZiMen_MA5680T(config)#ont-lineprofile epon profile-id 13 profile-name 5616 //创建线路模板
BaiZiMen_MA5680T(config-epon-lineprofile-13)#llid dba-profile-id 13 //线路模板中绑定dba模板ID为13的dba模板
BaiZiMen_MA5680T(config-epon-lineprofile-13)#commit //保存模板(此处必须保存否则将丢失模板配置)
BaiZiMen_MA5680T(config-epon-lineprofile-13)#quit
注册onu
BaiZiMen_MA5680T(config)#display ont autofind all
————————————————————————–
序列号 : 1
框/槽/端口 : 0/1/0
ONT MAC : 286E-D487-3BB2
密码 : 00000000000000000000000000000000
生产厂商ID : HWTC
ONT型号 : MDU
ONT软件版本 : V8R306C01B053
ONT硬件版本 : MA5616
ONT自动发现时间 : 2010-12-03 16:47:51
BaiZiMen_MA5680T(config-if-epon-0/1)#display ont autofind 0 //查看0端口发现的onu
BaiZiMen_MA5680T(config-if-epon-0/1)#ont add 0 0 mac-auth 286E-D487-3BB2 snmp ont-lineprofile-id 13 desc TO:JinHaiAnQingChuanLou_MA5616 // 注册端口为0 ;onu编号为0 ; mac地址为0018-82B3-A4D7的onu ; 管理方式为snmp; 线路模板为13 ; desc:描述此onu所处位置以及设备型号
BAIZIMEN_MA5680T(config-if-gpon-0/1)# ont ipconfig 0 0 ip-address 172.18.39.5 mask 255.255.255.0 gateway 192.18.39.1 manage-vlan 39 //给onu 0下发ip地址
BaiZiMen_MA5680T(config-if-gpon-0/1)# quit
配置业务虚接口:
service-port vlan 39 epon 0/1/0 ont 0 multi-service user-vlan 39 tag-transform translate //配置管理的业务虚接口
service-port vlan 3304 epon 0/1/0 ont 0 multi-service user-vlan 3304 tag-transform translate //配置语音的业务虚接口
service-port vlan 2064 epon 0/1/0 ont 0 multi-service user-vlan 2064 tag-transform translate //配置宽带的业务虚接口
……
service-port vlan 2095 epon 0/1/0 ont 0 multi-service user-vlan 2095 tag-transform translate //配置宽带业务虚接口
保存数据:
Ueusiuee_MA5680T(config)#save (必须保存,否则设备重启后数据会丢失)
此为有管理的配置,如果私人的OLT不用snmp,那就
ont add 0 0 mac-auth 286E-D487-3BB2 oam ont- lineprofile-id 10 ont-
H3C交换机配置
买了个H3C的万M交换机,先一直跑不上万M,进端口后强制 万M才能跑起来
speed 10000 强制万M,
undo speed 取消
然后,可以用qos命令对端口限速
qos apply polixcy 7400M outbound 限速下午
qos apply polixcy 7400M inbound 限速上行
undo qos apply polixcy 7400M inbound 取消限速上行
其它命令:
display cu 查看当前配置
sys 进入系统视图
shutsdown 关闭端口
undo shutsdown 开启端口
一个硬盘上双系统安装
用PE,如老毛桃,可以直接在硬盘的不同分区安装不同的WIN11,
但在启动界面会有显示两个一样的win10 pro
如果找不到启动文件又想改变启动时显示的系统名字,可以
WIN+R,输入cmd,在窗口中输入cd /,目的在于打开根目录,然后再输入bcdedit
会显示所有的启动项目,
标识符<default>和<current>分别代表默认系统和当前系统
你可以根据标识符来修改显示的系统名字,如:
bcdedit /set {default} description “aaaa – WIN10”
bcdedit /set {current} description “aaaa – WIN7”
也可下载工具easybcd来修改
一文读懂VIE架构
一、何为VIE架构?
1、VIE架构定义及优势
“VIE架构”,即可变利益实体(Variable Interest Entities;VIEs),也称为“协议控制”,即不通过股权控制实际运营公司而通过签订各种协议的方式实现对实际运营公司的控制及财务的合并。
VIE架构现主要用于中国企业实现海外上市、融资及外国投资者为规避国内监管对外资产业准入的限制。VIE架构存在已久,但其一直处于“灰色”地带,虽然在一些部门规章中已有关于VIE架构相关内容的规定,但目前的中国法律并未对VIE架构做出定性。
一般而言,VIE架构实际上为拟上市公司为实现海外上市,在开曼群岛或英属维尔京群岛设立一个平行的离岸公司,以该离岸公司作为未来上市或融资主体,其股权结构反映了拟上市公司真实的股权结构,而国内的拟上市公司本身则并不一定反映这一股权架构。
然后,该离岸公司经过一系列投资活动,最终在国内落地为一家外商投资企业(WFOE),WFOE与拟上市公司签订一系列协议,拟上市公司把自身大部分利润输送给WFOE。如此一来,最顶层的离岸公司成为拟上市公司的影子公司,就可以此登陆国外资本市场。
目前,由于外资准入方面的历史原因,中国大多数接受了美元基金投资的互联网公司(包括BAT等互联网巨头)大多采用的是新浪最早采用的VIE架构。
【两大优势】
一是税收优势,VIE能成功规避现行的不可自由兑换的外汇管制制度。例如在“新浪模式”中,新浪在开曼群岛设立公司,可享受巨额免税以及低成本的股份转让,也可同时在香港及其他国家地区申请挂牌上市;
二是可帮助外资有效规避政府管制和纠纷。通过在海外设立壳公司,用国内企业的资产进行反向包装,最终使其整体资产打包在海外上市,既有效避免了国内监管机构对外资进入的监管,也使国内企业在美国资本市场成功融资。
2、典型VIE架构及设置步骤
【重要名词】
BVI:英属维尔京群岛(The British Virgin Islands, B.V.I)是世界上发展最快的海外离岸投资中心之一。在国外设立BVI公司主体的原因,就是因为在BVI层面转让股权所得,基本不用缴纳任何税收,将来创始人或财务投资者退出时的税收负担基本为零,但这也存在较大风险;
Cayman:开曼群岛(Cayman Islands),是著名的离岸金融中心和“避税天堂”;
WFOE:Wholly Foreign Owned Enterprise,外商投资企业/外商独资企业;
国内实体:指的是拟上市公司;
【设置步骤】
(1)每个创始人以个人名义单独设立一个BVI公司,一般来说,每个股东都需要设立一个单独的BVI公司(注册简单,高度保密)。
(2)所有创始人的BVI公司共同成立一个BVI公司。
(3)BVI公司和投资人共同投资成立Cayman公司(VC/PE的投资款进入Cayman公司)。
(4)由Cayman公司成立HK公司。
(5)由HK公司在境内设立外商独资企业(WFOE),VC的投资款作为注册资本金进入WFOE。
(6)由WFOE协议控制或购买内资企业以达到控股国内实体公司。

【为何设立HK公司?】
利用税收优惠政策。
开曼公司在香港注册一个全资子公司,再经由香港公司在国内注册设立一个外商投资企业(WFOE)。之所以必须要经过香港而不是直接在国内注册,则是因为香港的特殊性。
根据2008年1月1日起新生效的《企业所得税法》规定,在中国境内没有机构场所的境外PE获得的股息性质的所得需要在中国缴纳10%的预提所得税(税收协定另有优惠的除外)。
由于大陆和香港之间有关避免双重征税的安排规定,对香港公司来源于中国境内的符合规定的股息所得可以按5%的税率来征收预提所得税。因此,很多红筹架构都把直接持有境内公司权益的公司设在香港以享受大陆和香港之间有关股息所得的预提所得税优惠。
二、VIE架构下利润如何转移?
VIE架构下,利润一般产生在境内的运营实体,境外的控股公司、香港公司及外商独资企业(WFOE)往往没有实质性的资产及业务运营,因此一般也不产生利润。
总的来讲,VIE架构下利润转移的路径是:境内运营实体 → WFOE → 香港公司 → 境外控股公司。由于WFOE是股权上100%受控于香港公司,香港公司股权上又100%受控于境外控股公司(即上图中的Cayman公司)。因此,利润从WFOE到香港公司,并进一步从香港公司到境外控制公司,都是以“子公司向母公司”进行红利分配的形式完成。
VIE 结构下,由于境内公司与WFOE不存在股权控制关系,是通过VIE协议实现控制的。因此,境内运营实体产生的利润也是通过VIE协议转移到WFOE,具体表现在以下两方面:
(1)WFOE向境内运营实体独家提供技术咨询服务、企业管理等服务,并向境内运营实体收取咨询服务费;
(2)在VIE架构下,往往将法律上可以由WFOE持有的IP都转让给WFOE,而后WFOE再许可给境内运营实体使用,并向境内运营实体收取知识产权许可使用费。WFOE通过上述一种或多种方式从境内运营实体收取的费用往往能占到境内运营实体利润的全部,由此实现利润从境内运营实体到WFOE的转移。
一旦VIE架构形成,根据美国通用会计准则(US GAAP) 或者国际会计报告准则,境外控制公司就能直接合并境内运营实体、WFOE及香港公司的财务报表。而实践中,VIE架构的公司鲜有真正将利润实质性转移到境外控股公司。
三、VIE架构诞生背景
中国政府出于主权或意识形态管制的考虑,禁止或限制境外投资者投资很多领域,比如电信、媒体和科技(TMT)产业的很多项目,但这些领域企业的发展需要外国的资本、技术、管理经验。
于是,这些领域的创业者、风险投资家和专业服务人员(财会、律师等)共同开拓了一种并行的企业结构规避政府管制,其具体操作步骤如下:
1、资本先在中国国内找到可信赖的中国公民,以其为股东成立一家内资企业(也可以收购),这家企业可经营外资不被获准进入的领域,比如互联网经营领域、办理互联网出版许可证、网络文化经营许可证、网络传播视听节目许可证等都要求内资企业。
2、同步地,资本在开曼或者英属维尔京群岛等地注册设立母公司,母公司在香港设立全资子公司,香港子公司再在中国国内设立一家外商独资公司(香港公司设立这个环节主要为了税收优惠考虑)。
3、独资公司和内资公司及其股东签订一组协议,具体包括:《股权质押协议》、《业务经营协议》、《股权处置协议》、《独家咨询和服务协议》、《借款协议》、《配偶声明》。
4、通过这些协议,注册在开曼或者英属维尔京群岛的母公司最终了控制中国的内资公司及其股东,使其可以按照外资母公司的意志经营内资企业、分配、转移利润,最终在完税后将经营利润转移至境外母公司。
四、VIE架构的监管态度
在新浪公司走通VIE架构这条路并成功在美国上市后,VIE架构几乎成为中国蓬勃发展的互联网企业在海外上市的唯一方式。
在互联网技术高速发展的大背景下,VIE协议使外国资本、技术、管理经验源源不断进入中国,使中国有了自身独立的互联网产业,在很多领域推动中国快速变革,从政府到整个产业的国内外资本、创业者以及网民都获益匪浅,VIE架构创造了一个多赢的格局。
在这个背景下,中国政府对于VIE架构的态度一直比较暧昧,既不肯放弃权威和管制的权力,认可VIE架构的合法性。同时,政府也在享受VIE架构带动的互联网产业高速发展所创造的社会进步、就业、税收等红利,不愿意冒利益受损和社会动荡的风险将VIE架构一概斥之违法。
实际上,政府默许VIE架构存在的原因主要包括以下两方面:
一方面,由于互联网发展需要大量资金投入,这是政府及国内众多风险投资基金在当下环境中,无法承担的巨大投入。因此,默许VIE架构存在,让这些互联网企业到海外去上市,拿海外投资者的资金来发展中国互联网事业,成为了必然选择;
另一方面,政府又深刻意识到媒体、文化、出版、互联网等属于牵扯国家意识形态的领域,如果不加以引导和监管,久而久之可能丧失国家的舆论话语权。因此一直以来,政府对VIE架构的态度较为纠结和暧昧。
五、VIE存在的风险
第一,合同签订过程中的违约风险,即境内公司违反其合同义务的风险。外部上市壳公司与国内签署的利润转移协议完全出自合同签订双方的意思自愿原则,即使境外企业采取一些风险应对措施,但是并不能根本消除此项风险。
第二,政策监管漏洞存在的法律风险,这种风险主要来源于中国法律即政府监管政策的变化。所有采用合同控制模式的境外间接上市,其所涉及的行业根据中国法律都限制和禁止外资进入,作为变通做法的VIE 结构的合法性,完全取决于中国政府的立场和态度。一旦国家相关部委出台相应的规定,可能会对采取VIE 结构的公司造成影响。
第三,对外投资过程中存在的外汇管制风险。例如,2009年世纪佳缘境外上市案例中,其在中国境内开展实体业务的两大子公司未能如期取得国家外汇管理局审批的外汇登记证,由此导致外商投资企业批准证书也失效。这就使投资者对世纪佳缘的投资具有不确定性,为公司的发展蒙上了一层阴影。
第四,税务风险。VIE 结构公司涉及大量的关联交易以及反避税问题,因此在股息分配上存在潜在的税收风险。上市壳公司在中国内地没有任何业务,一旦需要现金只能依赖于VIE向其协议控制方及境内注册公司分配的股息。
第五,控制风险。因为协议控制关系,上市公司对VIE 制度下的企业没有控股权,可能存在经营商无法参与或公司控制经营管理的问题。有协议而形成的债权在法律效力上只具有一般的对抗效力,远不及所有权的排他效力
什么是云原生?容器,docker-compose和k8s区别
我们先从云计算说起。在云计算普及之前,一个应用想要发布到互联网,就需要企业自己先买几台服务器,找一个IDC机房,租几个机架,把服务器放进去。接下来就是装Linux系统,部署应用。我们就假定用Java写了Web应用,怎么部署上去呢?先配置Tomcat服务器,在把编译好的war包上传到服务器,有用FTP的,安全意识高一点的会选SCP,然后配置Nginx、MySQL这些服务,最后一通调试,把应用跑起来,就算齐活。
这种物理机配合自搭网络环境、自搭Linux、自配环境的方式,有很多缺点,但最主要的问题有这么几个:
- 扩容和维护难,因为是物理机,需要先采购后跑机房,遇到双十一业务量猛增是来不及扩容的,用行话讲就是计算资源缺乏弹性;
- 安全性太差,熟悉Linux的运维工程师本来就少,精通SELinux的更是凤毛麟角,而且,系统安全性仅仅是一个方面,应用部署的权限、流程造成的安全漏洞更大;
- 部署流程不规范,开发、测试和运维脱节,缺少自动化测试和部署,无法快速迭代业务。
解决方案是上云。上云不能解决所有问题,但部分解决了前两个问题:
- 云服务商提供的是虚拟机,比起物理机,虚拟机的创建、维护、销毁比物理机简单了太多,且随时可以扩容,很大程度上解决了“弹性计算”的问题,至于弹性程度有多大,还得看应用的架构和设计水平;
- 和绝大多数中小企业相比,云服务商在网络和服务器安全方面要强若干个数量级。只要选择合适的官方镜像,配合防火墙规则,系统级别的安全问题大大减少,可以将重点放到应用本身的安全性上。
但是如果仅仅满足上云,把物理机换成虚拟机,把物理网换成虚拟专用网(VPC),是远远不够的。这些是计算资源和网络资源层面的简化。应用方面,如果延续旧的一套开发、测试、部署流程,做不到快速迭代。
要做到快速迭代,敏捷开发,就需要DevOps,即开发运维由一个团队负责,开发阶段,就要把部署、运维的工作考虑进去,而不是发布一个war包或者jar包后扔给运维不管了。
重开发、轻部署,直接后果就是缺少自动化发布流程。想要把部署规范化,就需要整体考虑一系列问题。
还是以Java应用为例,如果是手动部署,那么就上传war包到服务器,覆盖原有的版本,重启Tomcat,再测试。如果发现有严重问题要回滚怎么办?把老版本再传一遍,然后重启Tomcat。
手动部署,每次部署都是一次生死考验,所以最好不要安排在半夜,以免手抖敲错了命令,本来中断10分钟的服务,变成了灾备恢复,中断3天。
稍微靠谱一点的是写脚本部署,但各家写出来的脚本都有各家特色,不通用,不易维护,所以更好的方式是用成熟的部署方案,比如Ansible,把脚本标准化,比如做成蓝绿发布,把服务器分组,比如A、B两组,先把流量切到B组,升级A组服务器,有问题就回滚,没问题了,再把流量切到A组,升级B组服务器,最后,恢复正常流量,整个部署完成。
但是回滚这个事情,远没有那么简单。做过开发的同学都知道,升级新版本,一般要加配置,改配置,如果回滚到旧版本,忘了把配置改回去,那旧版本可能也不能正常工作。
上云,除了物理变虚拟,简化运维外,最重要的特点——弹性计算,一定要充分利用。
理论指导实践,实践完善理论。如果我们分析大多数基于互联网的应用,可以看到,一个应用,通常用到的资源如下:
- 存储资源,通常对应着一个或多个数据库,例如MySQL、Oracle、PostgreSQL等;
- 计算资源,以Java应用为例,就是一个或多个Web应用,跑在Tomcat,或者通过SpringBoot自带嵌入式服务器;
- 网关,通常是Nginx之类的服务器,对外作为统一的服务入口,对内提供反向代理;
- 其他支撑业务的组件,例如,为提升应用性能采用的Redis集群作为缓存,应用内部各组件通信使用的消息系统如Kafka等,以及随着业务不断扩大增加的ES集群、日志分析和处理的集群等。
上云后,云服务商通常都提供托管的数据库,以及大规模存储系统(S3),可解决存储资源问题。通过云服务商提供的负载均衡(Load Balancer),也无需自行部署Nginx等网关,免去了运维的问题。各种标准的业务组件如Redis、Kafka等,均可直接租用云服务商提供的资源。
我们重点讨论计算资源,也就是云上的虚拟机资源。对于应用来说,可以设计成有状态和无状态两种。一个应用在一台虚拟机内跑着,如果有本地文件的修改,它就是有状态的。有状态的应用既不利于扩展,也不利于部署。反过来,如果一个应用在运行期数据总是存在数据库或者缓存集群,本地文件无任何修改,它就是无状态的。
无状态的应用对应的虚拟机实际上就是不变的计算资源。这里的“不变”非常重要,它是指,一台虚拟机通过一个固定的镜像(预先内置好必要的支持环境,如JRE等)启动后,部署一个应用(对应一个war包或者jar包),该虚拟机状态就不再变化了,直接运行到销毁。
有的同学会问:如果给这台虚拟机重新部署一个新的应用版本,它的状态不就发生了变化?
确实如此。为了确保虚拟机的不变性,一旦启动后部署了某个版本,就不允许再重新部署。这样一来,对虚拟机这种计算资源来说,就具有了不变性。不变性意味着某个虚拟机上的应用版本是确定的,与之打包的配置文件是确定的,不存在今天是版本1,明天变成版本2,后天回滚到版本1的情况。
计算资源不变,能确保启动一台虚拟机,对应发布的应用版本和配置是确定的且不变的,对于运维、排错非常重要。
那么如何在保持计算资源不变的前提下发布新版本?
我们以AWS的CodeDeploy服务为例,假设一组正在运行的某应用v1集群包含3台虚拟机:
┌─────────────────────────────────────┐
│ VPC │
│ ┌────────────────────────┐│
│ │ Target Group ││
┌──┴──┐ │┌──────┐┌──────┐┌──────┐││
│ ELB │───────▶││EC2:v1││EC2:v1││EC2:v1│││
└──┬──┘ │└──────┘└──────┘└──────┘││
│ └────────────────────────┘│
└─────────────────────────────────────┘
现在,我们要把应用从v1升级到v2,绝不能直接把现有的3台虚拟机的应用直接升级,而是由CodeDeploy服务启动3台新的一模一样的虚拟机,只是部署的应用是v2。现在,一共有6台虚拟机,其中3台运行v1版本,另外3台运行v2版本,但此刻负载均衡控制的网络流量仍然导向v1集群,用户感受不到任何变化:
┌─────────────────────────────────────┐
│ VPC │
│ ┌────────────────────────┐│
│ │ Target Group ││
┌──┴──┐ │┌──────┐┌──────┐┌──────┐││
│ ELB │───────▶││EC2:v1││EC2:v1││EC2:v1│││
└──┬──┘ │└──────┘└──────┘└──────┘││
│ └────────────────────────┘│
│ ┌────────────────────────┐│
│ │ Target Group ││
│ │┌──────┐┌──────┐┌──────┐││
│ ││EC2:v2││EC2:v2││EC2:v2│││
│ │└──────┘└──────┘└──────┘││
│ └────────────────────────┘│
└─────────────────────────────────────┘
v2集群部署成功后,做一些自动化冒烟测试和内网测试,如果有问题,直接销毁,相当于本次部署失败,但无需回滚。如果没有问题,通过负载均衡把流量从v1集群切到v2,用户可无感知地直接访问v2版本:
┌─────────────────────────────────────┐
│ VPC │
│ ┌────────────────────────┐│
│ │ Target Group ││
┌──┴──┐ │┌──────┐┌──────┐┌──────┐││
│ ELB │───┐ ││EC2:v1││EC2:v1││EC2:v1│││
└──┬──┘ │ │└──────┘└──────┘└──────┘││
│ │ └────────────────────────┘│
│ │ ┌────────────────────────┐│
│ │ │ Target Group ││
│ │ │┌──────┐┌──────┐┌──────┐││
│ └───▶││EC2:v2││EC2:v2││EC2:v2│││
│ │└──────┘└──────┘└──────┘││
│ └────────────────────────┘│
└─────────────────────────────────────┘
稳定一段时间(例如15分钟)后,销毁v1集群。至此,整个升级完成。
上述的蓝绿部署就是CodeDeploy的一种标准部署流程。CodeDeploy也支持灰度发布,适用于更大规模的应用。
把计算资源不可变应用到部署上,实际上是充分利用了弹性计算这个优势,短时间创建和销毁虚拟机,只有上云才能做到,并且针对云计算,把部署流程变得更加简单可靠,每天发几个版本甚至几十、几百个版本都变得可能,DevOps能落地,有点“云原生”的味道了。
说到AWS的CodeDeploy,最早我使用AWS时,对于它的计费采用Reserved Instance预付模型感到很不理解,租用一台虚拟机,按国内阿里云、腾讯云包年包月预付享折扣不是更直观吗?如果仅仅把上云变成租用虚拟机,那就完全丧失了弹性计算的优势,相当于租用了一台虚拟机在里面自己折腾。AWS的Reserved Instance计费并不绑定某一台虚拟机,而是一种规格的虚拟机。我们还是举例说明,如果我们有1台2v4G规格的虚拟机,并购买了1年的Reserved Instance,那么,我随时可以销毁这台虚拟机,并重新创建一台同样规格的新的虚拟机,Reserved Instance计费会自动匹配到新的虚拟机上,这样才能实现计算资源不变,频繁实施蓝绿部署,真正把部署变成一种云服务。最近阿里云终于推出了节省计划的付费模式,有点真正的云计算的付费味道了,但是腾讯云、华为云还停留在包年包月和按量付费这两种原始租赁模型。
讲了这么多自动化部署,实际上一个指导思想就是如何充分利用云的弹性计算资源。从充分利用云的弹性资源为出发点,设计一整套开发、部署、测试的流程,就是云原生。弹性资源利用得越充分,云原生的“浓度”就越高,就越容易实施小步快跑的快速迭代。
那么虚拟机是不是弹性最好的计算资源呢?从应用的角度看,显然容器是一种比虚拟机更具弹性,更加抽象,也更容易部署的计算资源。
容器和虚拟机相比,它实际上是一种资源隔离的进程,运行在容器中的应用比独占一个虚拟机消耗的资源更少,启动速度更快。此外,容器的镜像包含了完整的运行时环境,部署的时候,无需考虑任何额外的组件,比其他任何部署方式都简单。使用容器,开发部署流程就变成了开发,生成镜像,推送至Docker Hub或云服务商提供的Registry,直接启动容器,整个过程大大简化。
使用容器比使用CodeDeploy部署还要更加简单,因为CodeDeploy需要在虚拟机镜像中预置Agent,由于没有统一的发布标准,还需要配置CodeDeploy,告诉它去哪拉取最新版本,这又涉及到一系列权限配置。而容器作为标准的部署方案,连发布系统都以Registry对各个镜像版本进行了有效管理,所以部署非常简单。
容器作为一种弹性计算资源,也应遵循计算不变性,即不要给容器挂载可变的存储卷。一组不变的容器集群才能更容易地升级。容器的运行方式本身就遵循了不变性原则,因为通过一个镜像启动一个容器,在运行过程中,是不可能换一个镜像的。容器本身也强烈不建议应用写入数据到文件系统,因为重启后这些修改将全部丢失。
容器的启动和销毁非常容易,不过,容器的管理却并不简单。容器的管理涉及到创建、调度、弹性扩容、负载均衡、故障检测等等,Kubernetes作为事实上的容器编排标准平台,已经成为各个云服务商的标配。
如果要直接使用K8s,在云环境中首先要有一组虚拟机资源作为底层资源,然后搭建K8s环境,定义好容器编排并启动容器。云服务商几乎都提供托管的K8s服务,但直接管理K8s仍然需要非常熟悉K8s的工程师。
还有一种更简单的使用容器的方式,即完全将底层虚拟机和K8s托管给云服务商,企业客户只需关心如何部署容器,底层的K8s和虚拟机对企业不可见或者无需关心。AWS的Elastic Container和阿里云的弹性容器均为此类服务。对于中小规模的应用来说,计算资源直接使用容器,再配合云服务商提供的负载均衡,托管的数据库、消息系统、日志系统等组件服务,应该是目前最“云原生”的一种方案。
最后,我们总结一下云原生的特点:
所谓云原生,就是在上云的过程中,充分发挥云平台的弹性计算、弹性存储的优势,尽量把应用设计成适合云计算的架构,把部署设计成简单易用的流程,这样才能实现业务快速上线,快速迭代。
云原生是一个大方向,在上云的过程中,逐步改造应用架构和部署流程,从手动往自动转,逐步增加计算资源的弹性,就能把云原生一步步落地。
云原生之所以解释不清楚,是因为云原生没有确切的定义,云原生一直在发展变化之中,解释权不归某个人或组织所有。
何谓云原生?
技术的变革,一定是思想先行,云原生是一种构建和运行应用程序的方法,是一套技术体系和方法论。云原生(CloudNative)是一个组合词,Cloud+Native。Cloud表示应用程序位于云中,而不是传统的数据中心;Native表示应用程序从设计之初即考虑到云的环境,原生为云而设计,在云上以最佳姿势运行,充分利用和发挥云平台的弹性+分布式优势。
Pivotal公司的Matt Stine于2013年首次提出云原生(CloudNative)的概念;2015年,云原生刚推广时,Matt Stine在《迁移到云原生架构》一书中定义了符合云原生架构的几个特征:12因素、微服务、自敏捷架构、基于API协作、扛脆弱性;到了2017年,Matt Stine在接受InfoQ采访时又改了口风,将云原生架构归纳为模块化、可观察、可部署、可测试、可替换、可处理6特质;而Pivotal最新官网对云原生概括为4个要点:DevOps+持续交付+微服务+容器。
2015年云原生计算基金会(CNCF)成立,CNCF掺和进来后,最初把云原生定义为包括:容器化封装+自动化管理+面向微服务;到了2018年,CNCF又更新了云原生的定义,把服务网格(Service Mesh)和声明式API给加了进来。
可见,不同的人和组织对云原生有不同的定义,相同的人和组织在不同时间点对云原生也有不同的定义,真是乱的一匹,搞得鄙人非常晕菜,我的应对很简单,选一个我最容易记住和理解的定义:DevOps+持续交付+微服务+容器。
总而言之,符合云原生架构的应用程序应该是:采用开源堆栈(K8S+Docker)进行容器化,基于微服务架构提高灵活性和可维护性,借助敏捷方法、DevOps支持持续迭代和运维自动化,利用云平台设施实现弹性伸缩、动态调度、优化资源利用率。
容器入门:Docker、Pod初探
01容器是什么?
– 容器是一种计算单元
作为一种计算单元,容器与线程、进程、虚拟机、物理机一样(如下图所示)。在连续尺度上,越往左隔离性、安全性和开销越低,越往右则越高。而容器则恰恰是介于进程和虚拟机之间的一种计算单元。
但并非所有的应用都适合选择容器,开发者可以根据自己应用的特点和需求选择最适合的计算单元。例如,你的应用是高性能、互信的,且处于同一个管理区域,那么用线程或者进程就可以满足;但如果你的应用是多租户的,并且和其他应用运行在同一个空间,那么你就需要考虑如何将这些应用安全地隔离开,使得数据不会被泄露或性能受到影响。那么这时,容器也许就是一个不错的选择了。
因为容器是一个「高度隔离的进程」,它在一般进程的隔离基础上又增加了新的隔离机制,这些隔离机制是使用Linux的内核提供的,它包括一些命名空间(Name Spaces)和CGroup。命名空间可以分为网络、存储和计算三大类。其中,最为重要的是网络命名空间。它保证了容器的网络是独立于其他容器网络的。每个容器自己看到的文件系统和其他容器的是不共享的,每个容器只能看到自己的进程ID,而进程编号也是连续的。
而说到容器与虚拟机最大的区别,刘俊辉认为,相对于虚拟机,容器最大的特征是它没有自己独立的操作系统,而是共享其宿主机上的一个操作系统;而虚拟机则运行在「一台独立的服务器上」。因此,容器相比于虚拟机的成本会小,但隔离性却有所欠缺。
– 容器是一种应用的包装形式
有过应用开发经验的人都知道,应用并不是一个单一的可执行文件,一个稍微复杂一点的应用包括多个部分,包括:代码、可执行文件、配置依赖、外部依赖(动态链接库)等。
所以在应用发行包装的时候,需要考虑目标操作系统的版本、系统架构以及它所依赖的模块等因素。否则应用安装时会改动系统的不同部分。
而容器作为一个应用的包装,它最大的特点就是实现了应用的独立和便携,容器本身包含了应用所有的依赖,这使得它可以再任意的基础设施上运行,不会因为系统版本、架构的问题,而导致各种意外。
02Docker是什么?
简单来说,Docker可以看作是一个非常成功的容器管理平台。Docker最重要的部分就是它的运行管理环境
正如上面所说,容器是一个计算单元,那么Docker的运行环境就是用来创建、管理和销毁这些计算单元的。在创建和管理这些计算单元的时候,需要用到计算单元的包装(也就是它的软件发行包),这些包装以容器镜像的方式存放在它的运行环境中,所有的容器计算单元都是通过这些镜像来创建的。
但镜像本身会有版本的发布、升级等需求,这就涉及到Docker的另一个重要组成部分DockerHub了。DockerHub有点像苹果的App Store,它是一个非常大的「容器市场」,所有常用的软件都可以在DockerHub上找到。
最后一个Docker的重要模块,就是用户界面和管理工具,它们用来向容器的运行环境发布命令或查看状态。只需要用一个Docker的命令加上一些参数,就可以实现创建、删除、查看容器的运行情况等操作。
接下来我们就来看看Docker的实际操作情况,我们会以运行一个Hello World的容器为例,讲讲Docker的使用情况。其实,只需要安装好Docker就可以尝试运行这个Hello World的容器了。
通过下面代码,我们来看看Docker做了些什么:
首先我们看到Docker在本地要去找Hello World最新版本的镜像,它发现本地并没有这个镜像后去DockerHub上把这个镜像给下载了下来。然后,这个镜像就被运行了,之后Docker后台就创建了这样一个容器。
Docker的出现,让容器应用管理变得非常轻松,运行容器只需要一个命令就可以实现。而从DockerHub上下载镜像、创建各种各样的隔离环境、创建容器与外部的网络通信环境都可以由Docker来完成。可以说Docker可以管理容器的整个生命周期。
Pod,一种增强型容器
Pod是一种组合的多容器运行单元,也是Kubernetes里的一个基础单元。你可以把它看作是一种容器的扩展或者增强型的容器。Pod里面包括一个主容器和数个辅助容器,它们共同完成一个特定的功能。把多个进程(容器也是一种隔离的进程)打包在一个Name Space里的时候,就构成了一个Pod。Pod里面不同进程的应用包装仍然是独立的(每个容器都会有自己的镜像)。
Pod的意义在于,它可以既保持主容器和辅助容器的的密切关系,又保持主容器的独立性。由于主容器和辅助容器的生命周期相同,可以同时被创建和销毁,因此把它们放在一个Pod中,可以使他们的交互更加高效。
而另一方面,主容器需要完成一些主要的工作,而另一些工作可能是有共性的,就可以单独打包由辅助容器来运行。
在K8S里,编排调度的最小单位并不是容器,而是Pod。有了Docker容器,为什么还需要一个Pod? 前面我们说Docker容器就好比云计算操作系统中的应用,K8S相当于操作系统,那Pod就是进程组:即Pod是对一组容器(一个或多个)的抽象。之所以做这样一层抽象,是因为在 Borg 项目的开发和实践过程中,Google 公司的工程师们发现,他们部署的应用,往往都存在着类似于“进程和进程组”的关系。在同一个Pod中,可以直接通过localhost通信,并且可以共享网络栈和Volume
非常推荐大家去一个叫Katacoda的网站,它上面有大量免费的在线实验,包括Docker及Docker Image等动手操作项目,而且现在是完全免费的。大家不妨去这里动手实操起来。
docker-compose
Dockerfile可以让用户管理一个单独的应用容器,而compose则允许用户在一个模板(yaml格式)中定义一组相关联的应用容器(被称为一个project,即项目)
例如一个web服务再加上后端的数据库服务容器等
为什么要使用docker-compose
使用一个Dockerfile模板文件,可以让用户很方便的定义一个单独应用容器。在工作中,经常会碰到需要多个容器相互配合来完成某项任务的情况,例如要实现一个web项目,除了web服务容器本身,往往还需要再加上后端的数据库服务容器,甚至还包括负载均衡容器等。
compose允许用户通过一个单独docker-compose.yml模板文件(YAML格式)来定义一组相关联的应用容器为一个项目(project)
docker-compose项目由python编写,调用docker服务提供的API来对容器进行管理,因此, 只要所操作的平台支持docker-API,就可以在其上利用conpose来进行编排管理。
简单来说:就是来管理多个容器的,定义启动顺序的,合理编排,方便管理。
docker-compose和k8s的区别
Docker Compose是一个基于Docker的单主机容器编排工具.适合开发、测试和暂存环境
而k8s是一个跨主机的集群部署工具,是大型生产级部署的更好选择
网络排查工具MTR
常用的 ping,tracert,nslookup 一般用来判断主机的网络连通性,其实 Linux 下有一个更好用的网络联通性判断工具,它可以结合ping nslookup tracert 来判断网络的相关特性,这个命令就是 mtr。mtr 全称 my traceroute,是一个把 ping 和 traceroute 合并到一个程序的网络诊断工具。
traceroute默认使用UDP数据包探测,而mtr默认使用ICMP报文探测,ICMP在某些路由节点的优先级要比其他数据包低,所以测试得到的数据可能低于实际情况, 参数 -U 使用UDP数据包探测 。
安装方法
1.Windows系统可以直接在https://cdn.ipip.net/17mon/besttrace.exe下载BestTrace工具并安装。也可以在https://github.com/oott123/WinMTR/releases GitHub上下载MTR专用工具,该工具为免安装,下载后可以直接使用。
2.Linux可以直接运行命令进行安装。
1.# Debian/Ubuntu 系统
2.apt install mtr
3.
4.# RedHat/CentOS 系统
5.yum install mtr3.Apple客户端可以在App store搜索Best NetTools下载安装
4.Android客户端:可以在Google Play上下载TracePing,但是由于国内Google Play无法访问,笔者自行下载下来,可以直接访问 https://dwz.cn/KCdNPH4c 下载TracePing。
使用
MTR使用非常简单,查看本机到 http://qq.com 的路由以及连接情况直接运行如下命令:
1.mtr qq.com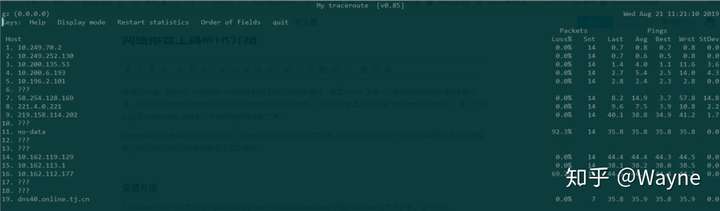
MTR http://qq.com 测试界面
具体输出的参数含义为:
- 第一列是IP地址
- 丢包率:Loss
- 已发送的包数:Snt
- 最后一个包的延时:Last
- 平均延时:Avg
- 最低延时:Best
- 最差延时:Wrst
- 方差(稳定性):StDev
参数说明
-r or –report
使用 mtr -r http://qq.com 来打印报告,如果不使用 -r or –report 参数 mtr 会不断动态运行。使用 report 选项, mtr 会向 http://qq.com 主机发送 10 个 ICMP 包,然后直接输出结果。通常情况下 mtr 需要几秒钟时间来输出报告。mtr 报告由一系列跳数组成,每一跳意味着数据包通过节点或者路由器来达到目的主机。
一般情况下 mtr 前几跳都是本地 ISP,后几跳属于服务商比如 腾讯数据中心,中间跳数则是中间节点,如果发现前几跳异常,需要联系本地 ISP 服务提供上,相反如果后几跳出现问题,则需要联系服务提供商,中间几跳出现问题,则需要联系运营商进行处理
默认使用 -r 参数来生成报告,只会发送10个数据包,如果想要自定义数据包数量,可以使用 -c 参数
-s or –packetsize
使用 -s 来指定ping数据包的大小
1.mtr -s 100 qq.com100 bytes 数据包会用来发送,测试,如果设置为负数,则每一次发送的数据包的大小都会是一个随机数。
-c
指定发送数量
1.mtr -c 100 qq.com-n
不进行主机解释
使用 -n 选项来让 mtr 只输出 IP,而不对主机 host name 进行解释
1.mtr -n qq.comMTR结果分析
当我们分析 MTR 报告时候,最好找出每一跳的任何问题。除了可以查看两个服务器之间的路径之外,MTR 在它的七列数据中提供了很多有价值的数据统计报告。Loss% 列展示了数据包在每一跳的丢失率。Snt 列记录的多少个数据包被送出。使用 –report 参数默认会送出10个数据包。如果使用 –report-cycles=[number-of-packets] 选项,MTR 就会按照 [number-of-packets] 指定的数量发出 ICMP 数据包。
Last, Avg, Best 和 Wrst 列都标识数据包往返的时间,使用的是毫秒( ms )单位表示。Last 表示最后一个数据包所用的时间, Avg 表示评价时间, Best 和 Wrst 表示最小和最大时间。在大多数情况下,平均时间( Avg)列需要我们特别注意。
最后一列 StDev 提供了数据包在每个主机的标准偏差。如果标准偏差越高,说明数据包在这个节点的延时越不相同。标准偏差会让您了解到平均延时是否是真的延时时间的中心点,或者测量数据受到某些问题的干扰。
例如,如果标准偏差很大,说明数据包的延迟是不确定的。一些数据包延迟很小(例如:25ms),另一些数据包延迟很大(例如:350ms)。当10个数据包全部发出后,得到的平均延迟可能是正常的,但是平均延迟是不能很好的反应实际情况的。如果标准偏差很高,使用最好和最坏的延迟来确定平均延迟是一个较好的方案。
在大多数情况下,您可以把 MTR 的输出分成三大块。根据配置,第二或第三跳一般都是您的本地 ISP,倒数第二或第三跳一般为您目的主机的ISP。中间的节点是数据包经过的路由器。
当分析 MTR 的输出时,您需要注意两点:loss 和 latency。
网络丢包
如果在任何一跳上看到 loss 的百分比,这就说明这一跳上可能有问题了。当然,很多服务提供商人为限制 ICMP 发送的速率,这也会导致此问题。那么如何才能指定是人为的限制 ICMP 传输 还是确定有丢包的现象?此时需要查看下一跳。如果下一跳没有丢包现象,说明上一条是人为限制的。如下示例:
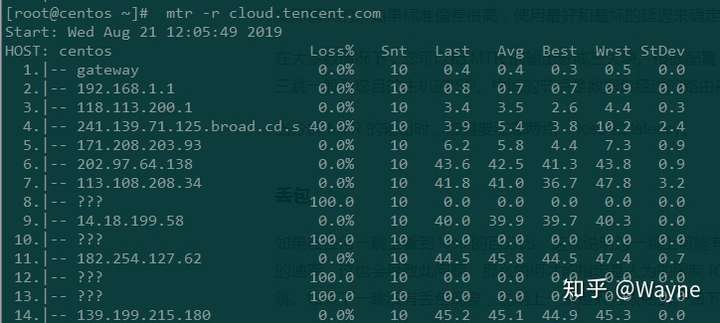
人为限制MTR丢包
在此例中,第4跳发生了丢包现象,但是接下来几条都没任何丢包现象,说明第二跳的丢包是人为限制的。如果在接下来的几条中都有丢包,那就可能是第二跳有问题了。请记住,ICMP 包的速率限制和丢失可能会同时发生。
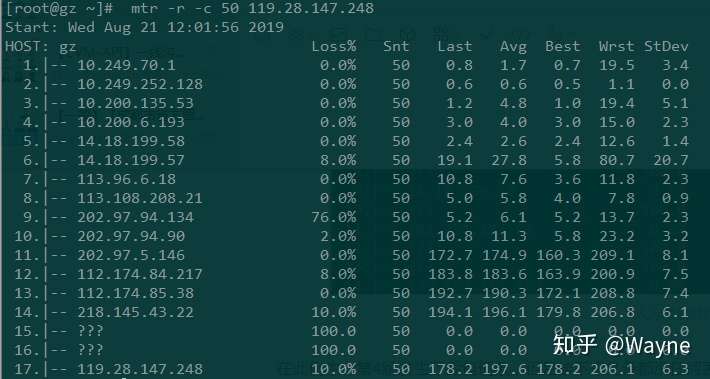
MTR丢包截图
从上面的图中,您可以看从第13跳和第17跳都有 10% 的丢包率,从接下来的几跳都有丢包现象,但是最后15,16跳都是100%的丢包率,我们可以猜测到100%的丢包率除了网络糟糕的原因之前还有人为限制 ICMP。所以,当我们看到不同的丢包率时,通常要以最后几跳为准。
还有很多时候问题是在数据包返回途中发生的。数据包可以成功的到达目的主机,但是返回过程中遇到“困难”了。所以,当问题发生后,我们通常需要收集反方向的 MTR 报告。
此外,互联网设施的维护或短暂的网络拥挤可能会带来短暂的丢包率,当出现短暂的10%丢包率时候,不必担心,应用层的程序会弥补这点损失。
网络延迟
除了可以通过MTR报告查看丢包率,我们也还可以看到本地到目的之间的时延。因为是不通的位置,延迟通常会随着条数的增加而增加。所以,延迟通常取决于节点之间的物理距离和线路质量。
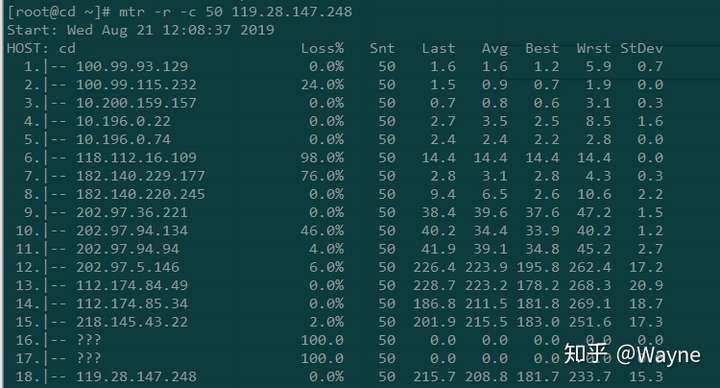
MTR查看网络延迟
从上面的MTR报告截图中,我们可以看到从第11跳到12跳的延迟猛增,直接导致了后面的延迟也很大,一般有可能是11跳到12跳属于不通地域,物理距离导致时延猛增,也有可能是第12条的路由器配置不当,或者是线路拥塞。需要具体问题进行具体的分析。
然而,高延迟并不一定意味着当前路由器有问题。延迟很大的原因也有可能是在返回过程中引发的。从这份报告的截图看不到返回的路径,返回的路径可能是完全不同的线路,所以一般需要进行双向MTR测试。
注:ICMP 速率限制也可能会增加延迟,但是一般可以查看最后一条的时间延迟来判断是否是上述情况。
根据MTR结果解决网络问题
MTR 报告显示的路由问题大都是暂时性的。很多问题在24小时内都被解决了。大多数情况下,如果您发现了路由问题,ISP 提供商已经监视到并且正在解决中了。当您经历网络问题后,可以选择提醒您的 ISP 提供商。当联系您的提供商时,需要发送一下 MTR 报告和相关的数据。没有有用的数据,提供商是没有办法去解决问题的。
然而大多数情况下,路由问题是比较少见的。比较常见的是因为物理距离太长,或者上网高峰,导致网络变的很慢。尤其是跨越大西洋和太平洋的时候,网络有时候会变的很慢。这种情况下,建议就近接入客户的节点。
分期合约到期
开场白:您好!请问是XX家吗?我是您这边的电信客户经理
说痛点:您的网龄可以领取960-1800元通讯补贴,今明两天集中在XX营业厅领取,您的补贴款已经派到我们门店,您看是明天上午还是下午带身份证到我们XX厅来领取。
约时间:您看您是今天还是明天来领取呢?
加微信:您的微信号是这个133XXX的号码不?我加一下您微信,把领取补贴的信息发送给您,麻烦您通过一下。
发信息:
感兴趣客户发送内容:
尊敬的客户,已为您预留960-1800元通讯补贴领取名额,每人限领一次,请您于8.31-9.1号到**营业厅领取,地址:
不感兴趣客户发送内容:
尊敬的客户,如果您还没领取5G通讯补贴,请您于8.31-9.1号及时带身份证到**营业厅领取以免逾期,地址:
异议处理:
1、这什么补贴:您可以来领一台5G手机,(我才换的手机不需要手机的),您家人都换了吗?除了手机店内的其他通讯产品:小度音箱、手表手环、无线耳机都可以。
2、不知道要领什么/感觉不满想来的:您可以先到营业厅把这1000-2000元的补贴款领了,您不领这个名额就逾期了白白浪费一千多块钱。
3、没时间来:您实在没时间到我们店来,帮您安排客户经理把补贴给您的手机送到您家,您看您明天几点在家。